1. Create a Private Processing
Now it's time to create your own Processing ! To show you the process, we are going to start from scratch and create a Processing that performs simple data-augmentation and put the augmented Data in a new DatasetVersion.
Let's go to our Processing page.
Access the Processings page
On this page are listed all the Processing you have access to. They are grouped by type of object they can be applied on:
- Datalake Processings
- DatasetVersion Processings
- ModelVersion Processings
For each type of Processing, are listed the Public and the Private Processings. The Public Processings can be used by every Picsellia user whereas the Private Processing_s can only be visualized and used by the members of the current_Organization.
On this view, for each Processing, is displayed its Name, Description, Task, and potential constraints.
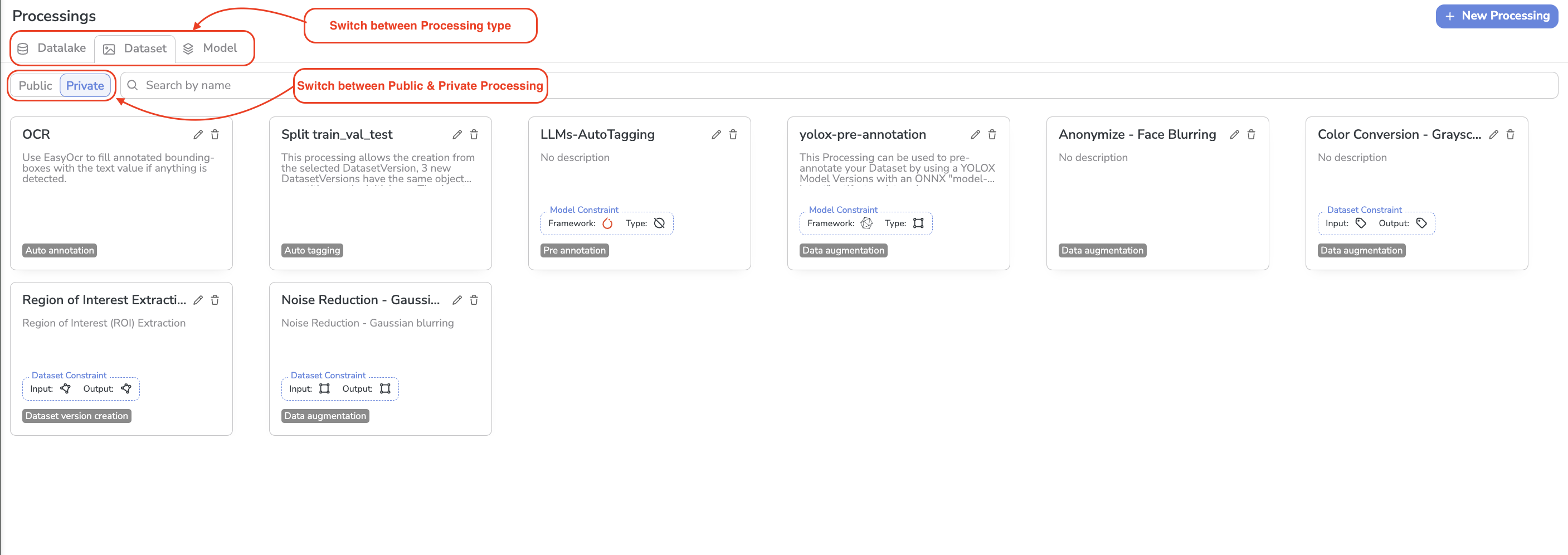
Processing list
So now let's create our brand new Processing, this one will be a simple data-augmentation one that can be used on a DatasetVersion . First click on + New Processing from the DatasetVersion Processings list:
Private DatasetVersion Processing creation
A modal will then open allowing you to define precisely your Processing:
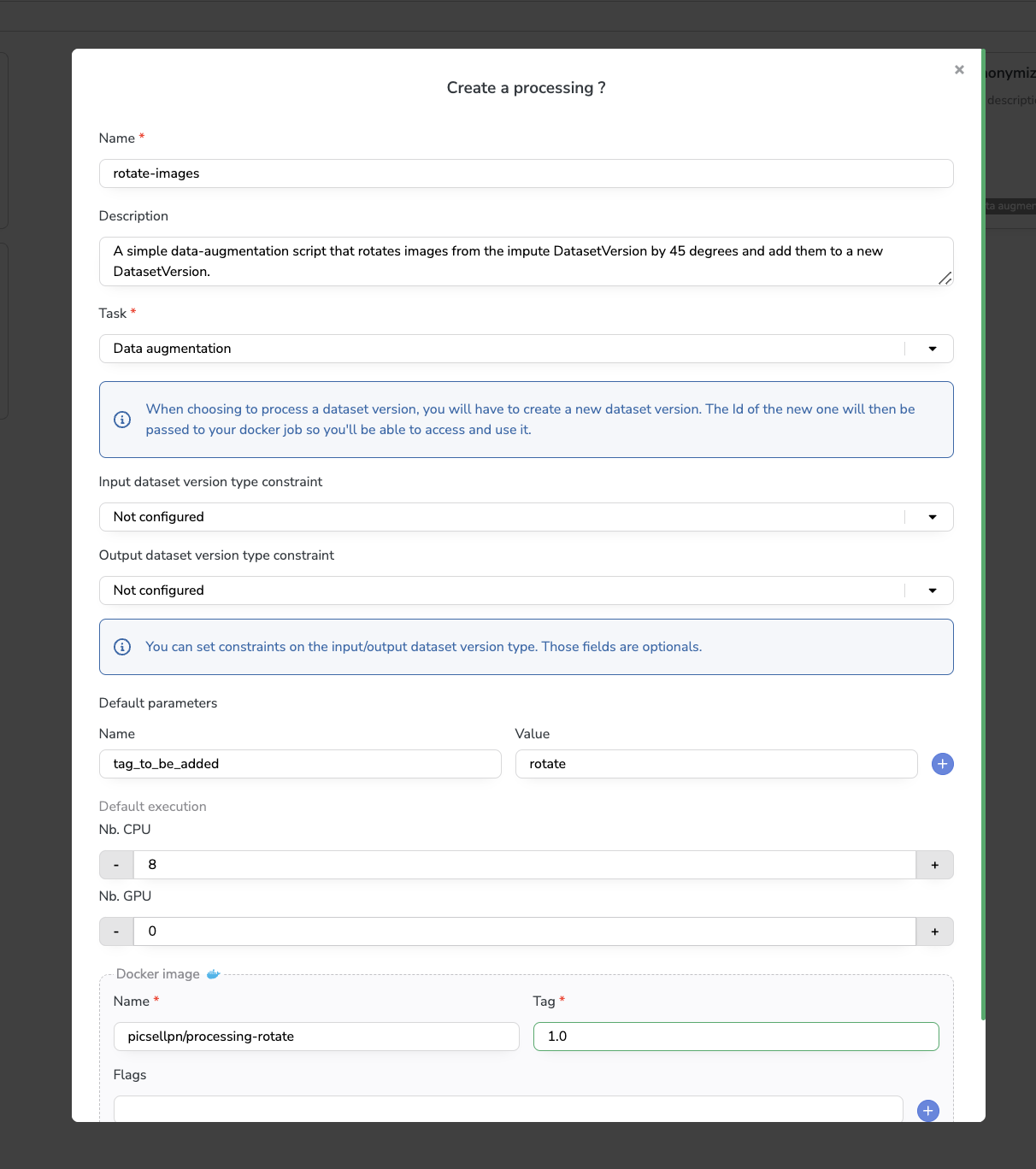
Let's describe the different fields:
- Name: As our
Processingis going to simply rotate images, we give it a simple yet clear name rotate-image - Description: We give it a little description explaining the action performed by our script
- Task: We set the task to data augmentation our script enters in this category. Depending on the Processing type, different Tasks can be available. As our
processingis of type data augmentation, it will automatically create a newDatasetVersionto host the augmented image. When you will launch it, you will be prompted to enter a name for this newDatasetVersion. - Input/Output DatasetVersion constraint: We could set a DatasetVersion Type Constraint, which constraint the Detection Type of the DatasetVersion the Processing can be applied on and defines the Detection Type of the potential new
DatasetVersionthat will be created. Here we choose to leave it not configured as it can be used on any Detection Type. - Parameters: It is basically a set of keys/values that will be sent to the script allowing the user that triggers the script to customize its execution. The value defined in the form will be the default value if the user doesn't modify it before launching the
Processing. In our case, we don't have any parameters for our script so we leave the default parameters empty. - Nb. CPU / Nb. GPU: Number of CPU and GPU chips that will be used to run your
Processing. As this script will not require much computing resource, you can leave the default execution requirements to 8 CPUs and 0 GPUs. (Change this value based on the needs of your code) - Docker Image: As the
Processingscript will be packaged in a Docker image (see the next part of the tutorial), we have to enter its future details.- As I'm pushing in the Public Docker Hub, my Docker Image name is my Docker username followed by the chosen name for our
Processing. Here it is processing-rotate - I will set the Image tag to 1.0, you could have many tags for the same image, just enter the correct one.
- We could add some flags to the Docker Run command but here we don't need anything so we leave this empty.
- As I'm pushing in the Public Docker Hub, my Docker Image name is my Docker username followed by the chosen name for our
And that's it! Now you can just click Create and see our brand new Processing is available on Picsellia 🎉
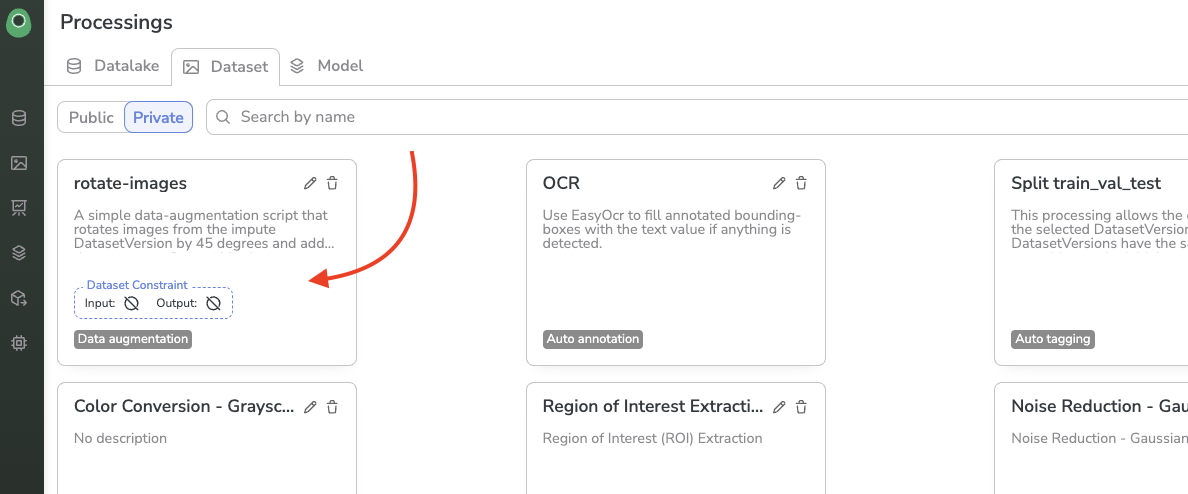
Created Processing
Now that your DatasetVersion Processing is created as a Private Processing, you can at any moment modify it by clicking on the pen icon and deleting it by clicking gon the trash icon.
Now, move on to the next part of the tutorial to see how to Build and Package your own Processing and push it to a Docker Registry.
Updated about 1 year ago