Deployments - Shadow deployment
1. What is the Shadow Deployment
Picsellia allows you to have twoModelVersion running parallelly inside a single Deployment, this is called the Shadow Deployment.
As already detailed in the previous documentation pages, when deploying a ModelVersion on Picsellia, an associated Deployment will be created. In the frame of this Deployment, the deployed ModelVersion is called the Champion Model.
But you can also have another ModelVersion deployed in the same Deployment and doing inferences on the same image as the Champion Model, this one is called the Shadow Model.
The main difference betweenChampion & Shadow Models is that the Prediction that should actually be taken into account are the ones done by the Champion Model. Having a Shadow Model deployed mainly aims at comparing the Prediction done by the Shadow Model against the Champion Model.
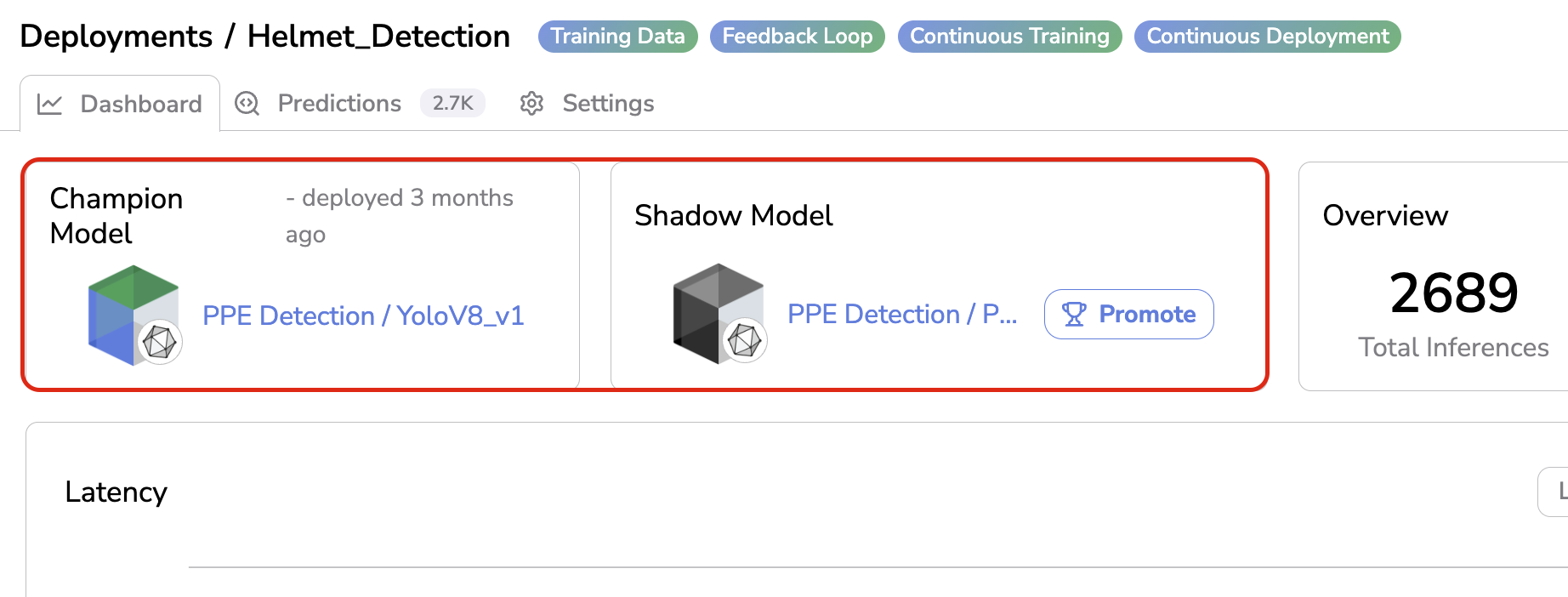
Champion & Shadow Model
2. Deploy a Shadow Model
A. Through the Continous Deployment
In the frame of the Continuous learning mechanism detailed here, you can choose to deploy the new ModelVersion trained through the defined Pipeline as a Shadow Model, this way you will be able to ensure the Shadow Model is actually overperforming the Champion Model before making it the new Champion Model.
Basically, as soon as the Experiment created by the Continous Learning is over, this one is exported as a new ModelVersion. If the Continuous Deployment has been defined as Shadow Deployment, this new ModelVersion will be deployed as a Shadow Model in the involved Deployment.
B. Manually through the SDK
You can also decide to deploy any ModelVersion as a Shadow Model to an existing Deployment using the Python SDK and especially the set_shadow_model() method.
3. Visualize Shadow Prediction
As soon as a Shadow Model is deployed in addition to the Champion Model on a Deployment, you will be able to visualize in the Prediction tab the Prediction done by the Champion and Shadow Model.
The serving infrastructure must perform inference for bothModelVersionIn case you
ModelVersionis deployed on the Picsellia Serving Engine, the Shadow Model is natively handled, meaning that as soon as a Champion and Shadow Model are deployed to aDeployment, bothModelVersionwill producePredictionfor the further inferences and they will be logged properly in the dedicatedDeployment.In case you are using your own serving infrastrcture you need to ensure that for a given image on which inference needs to be done, both
ModelVersion(i.e Champion & Shadow Models) are going to produce aPrediction. Then you also need to log bothPredictionon the same PicselliaDeployment, this can be done using the monitor() method from the Python SDK that allows to log at the same time a Champion Prediciton and a Shadow Prediction. Futher details avaible here.
From any view in the Prediction overview, you can switch between the Champion and Shadow Prediction easily in order to compare them. In the Metadata are also displayed the number of Shape contained in the Champion and Shadow Predictions
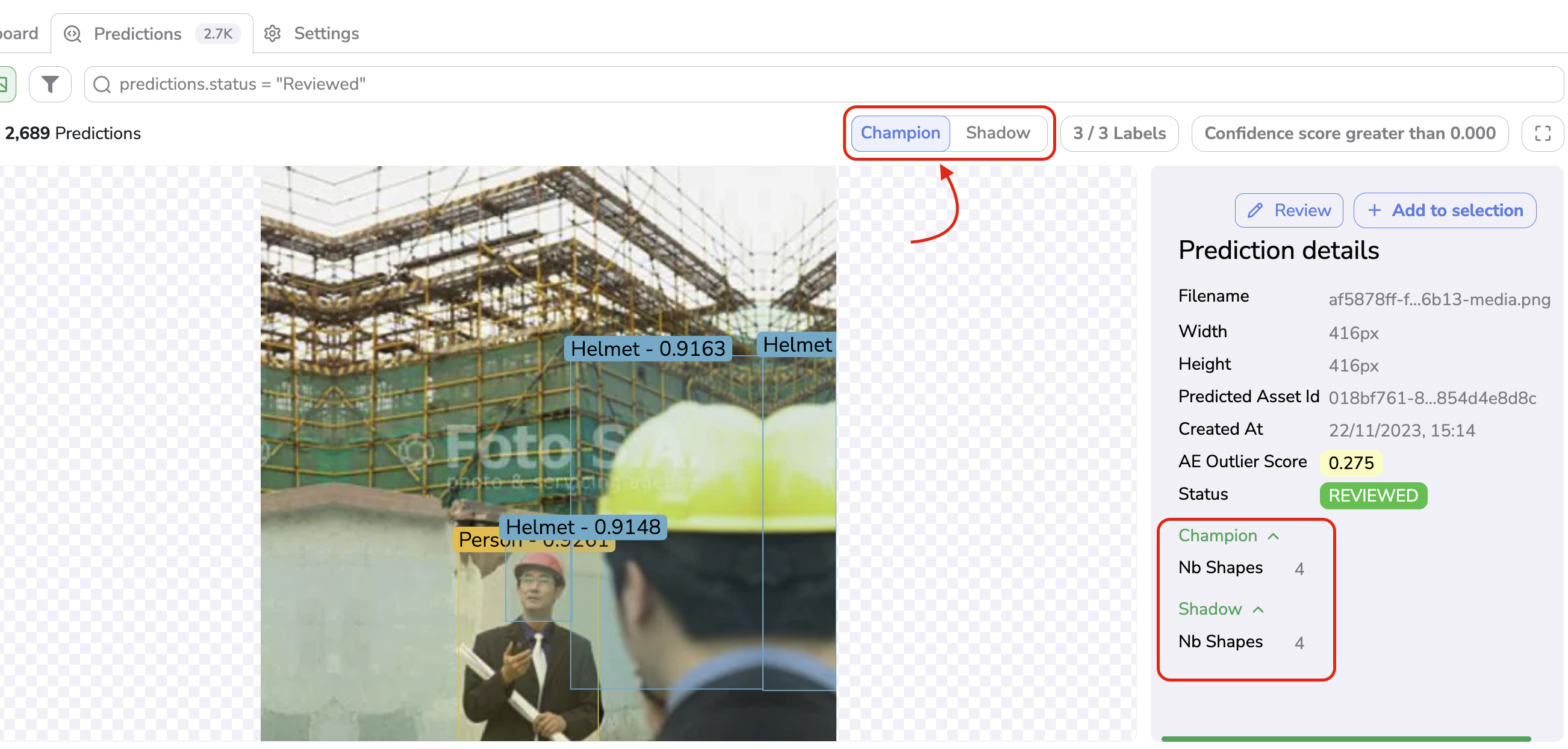
Champion & Shadow Prediction visualization
the Prediction Review tool, when a PredictedAsset is still in TO REVIEW status, you can switch the visualization between Champion & Shadow Prediction as shown below allowing you to perform the Review on the Prediction that is the closer to the GroundTruth for instance.
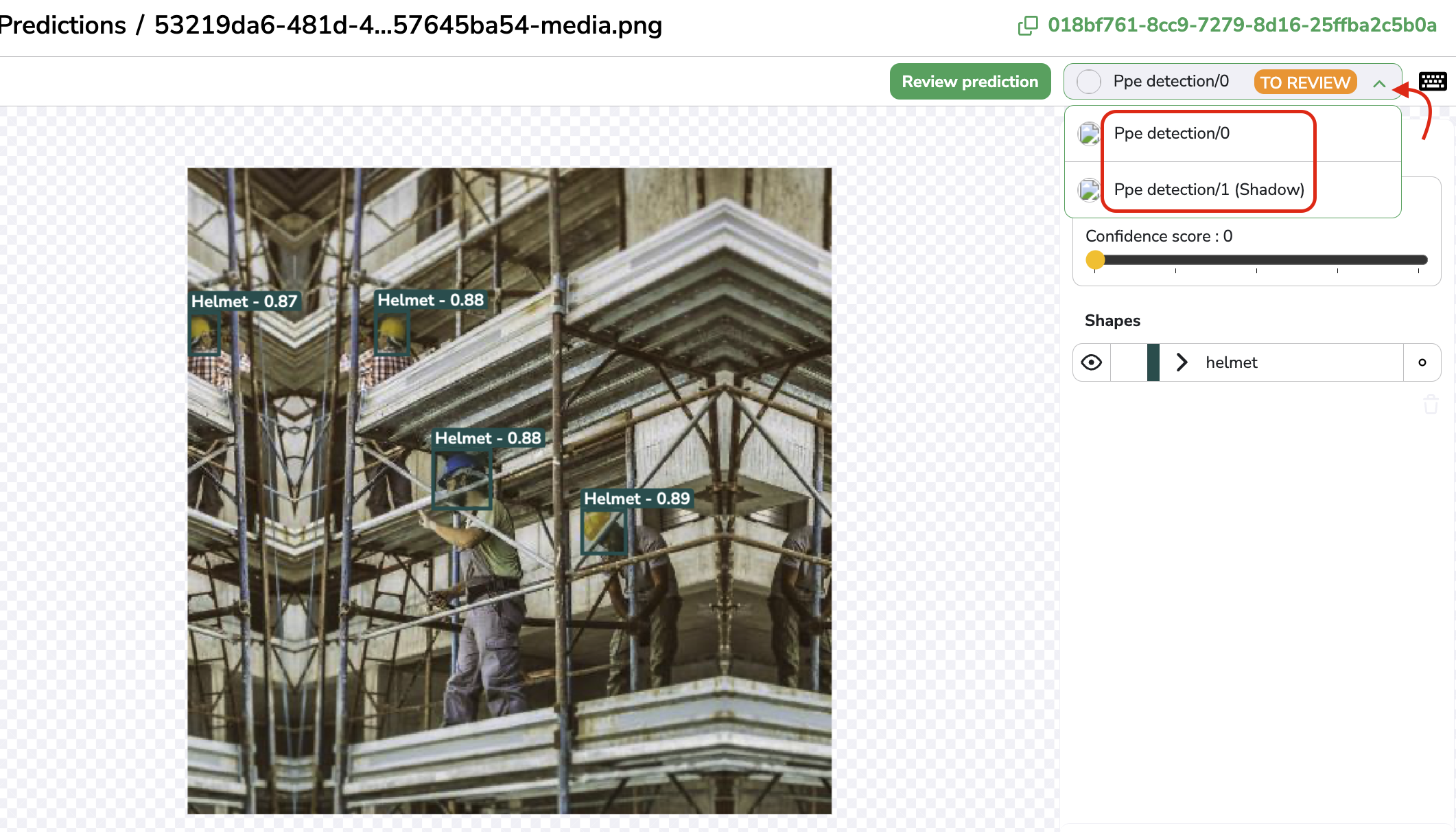
Champion & Shadow Prediction on the Prediction Review tool
4. Compare Champion and Shadow Models
In addition to comparing one-by-one on each PredictedAsset the Champion & Shadow Prediction, Picsellia also includes the Shadow Prediction, when it makes sense, on some metrics displayed in the Dashboard.
On the impacted metrics, the values related to the Champion Prediction are always displayed in green whereas the values related to the Shadow Prediction are in black.
For instance, you can compare the Champion & Shadow Model on the Latency, the Average Precision and Average Recall.
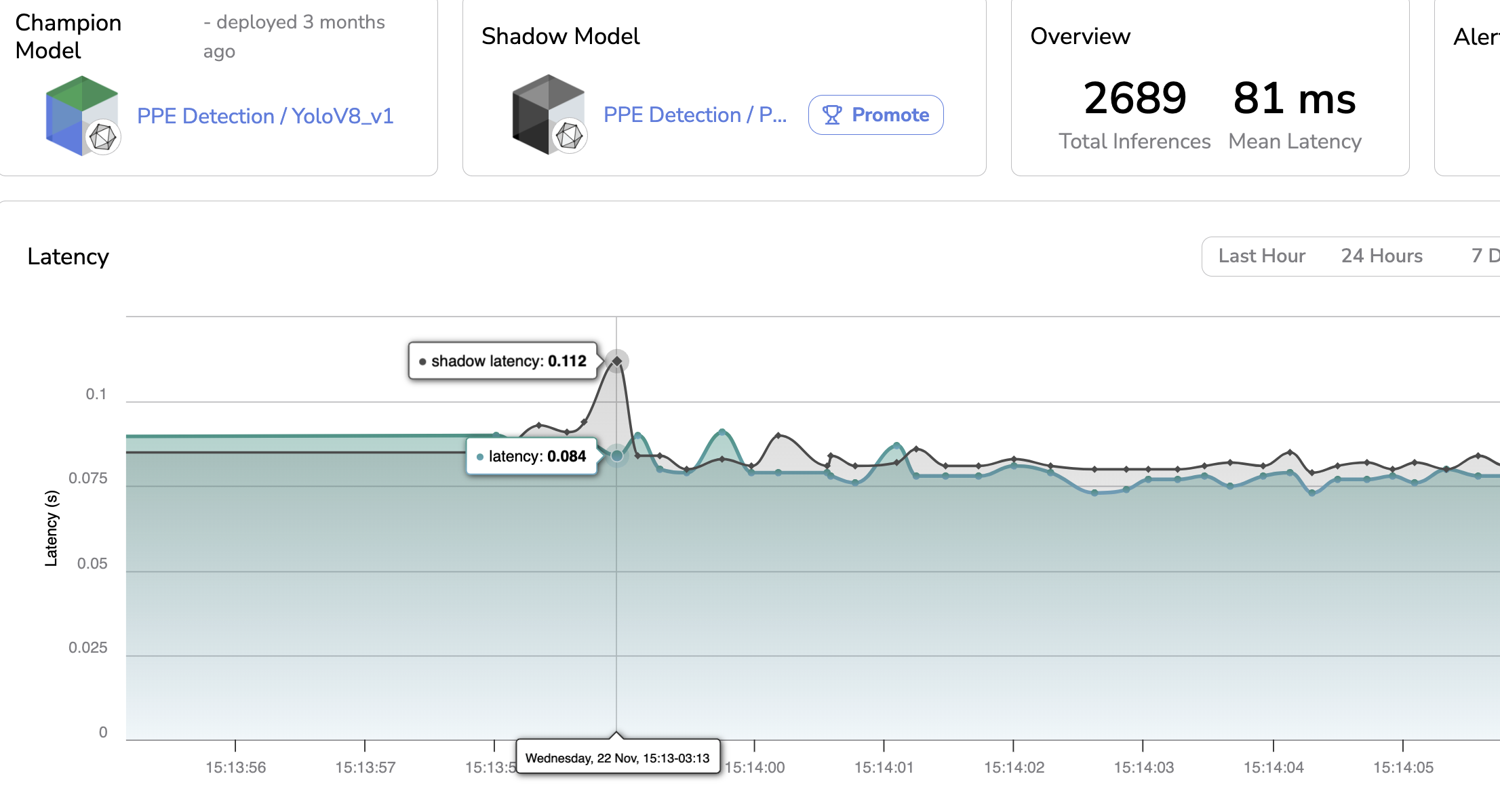
Champion & Shadow latency
5. Promote a Shadow Model
As soon as you consider that the Shadow Model is overperforming the Champion Model and the Prediction that should be actually taken into account should be the ones done by the Shadow Model, you can click on the Promote button, this way, the Shadow Model will become the Champion Model of the current Deployment.
Promote Shadow Model
Updated about 1 year ago