A Processing is a piece of code (like a Python script) executed on Picsellia infrastructure that can interact with any object related to your Organization (Datalake, DatasetVersion, ModelVersion..).
This page details how to use aProcessing on aDatasetVersion
The following pages are dedicated to the use of Datalake Processing and ModelVersion Processing.
To explain this, let's start with a use case:
Let's say you want to perform data augmentation on a Picsellia DatasetVersion.
Normally, the steps to achieve this would be:
Downloading your images locally
Running a script with some data-augmentation techniques (like rotating the image for example) on all of your images
Creating a new DatasetVersion you are using
Uploading the augmented images to this new DatasetVersion
We know it can feel a little bit overwhelming. Although running a script can be considered an automatic task, this process is fully manual. In addition, you must be using a computer that is able to run the code (it has to be in the correct environment, etc...)
This is why we came up with Processing, to let you automate this process and launch it whenever you want, on the data you want, directly from the platform!
So let's see how to use the most common Processing, the pre-annotation of a DatasetVersion.
AProcessing can be run on a DatasetVersion, so you can perform tasks like:
Pre-annotation with a ModelVersion
Data Augmentation
Smart Version Creations
Or anything you can think of regarding your data!
2. Access the Processing list
First of all, you can at any moment reach the list of available Processing by clicking on Processings on the Navigation bar as shown below:
Access Processings
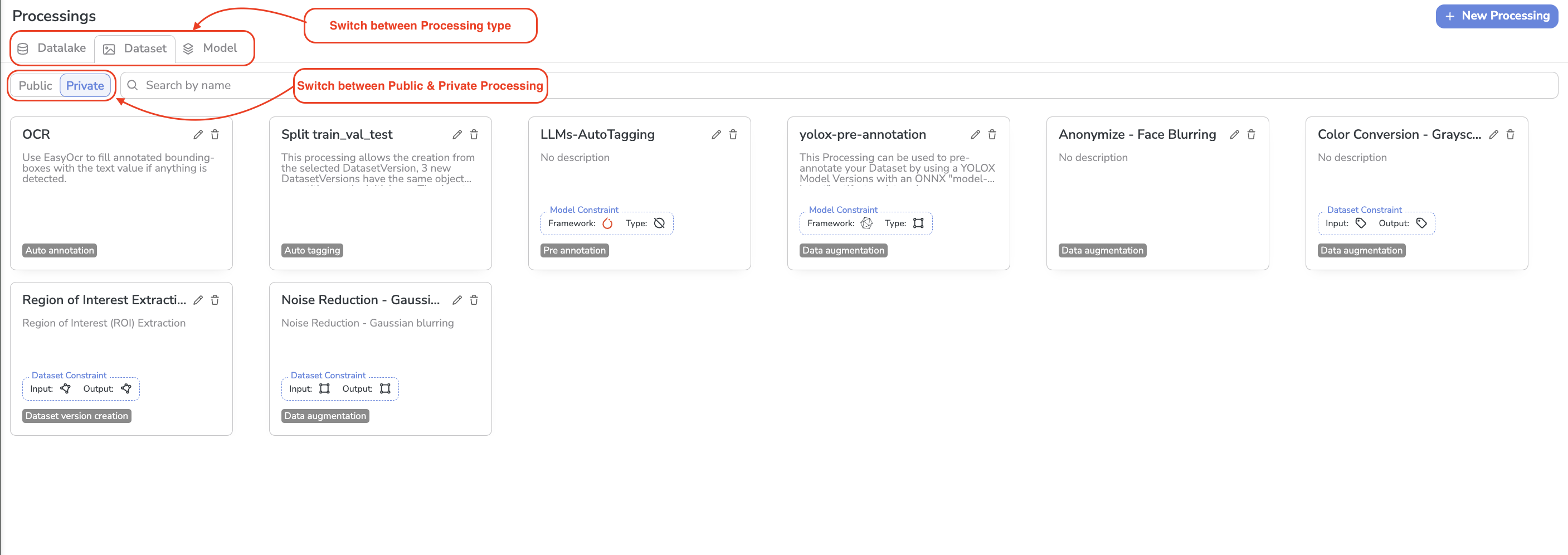
This page provides access to all the Processing available for the current Organization.
They are sorted by type of object they can be used on, meaning:
Datalake
DatasetVersion
ModelVersion
For each type of Processing, you will have access to all the Processing created by the Picsellia DataScience team (called Public Porcessings) alongside the ones you created (called Private Porcessings).
Processing list
On this view, for each Processing, is displayed its Name, Description, Task, and potential constraints.
It is also from this view that you can create or update any type of Private Processing. More details on this topic are available here.
3. Use a Processing on a DatasetVersion
Now that we can easily list the available Processing it is high time to use them. In our case, we will use one on a DatasetVersion.
Let's see one of the most useful examples: Pre-annotation with a ModelVersion from your Registry.
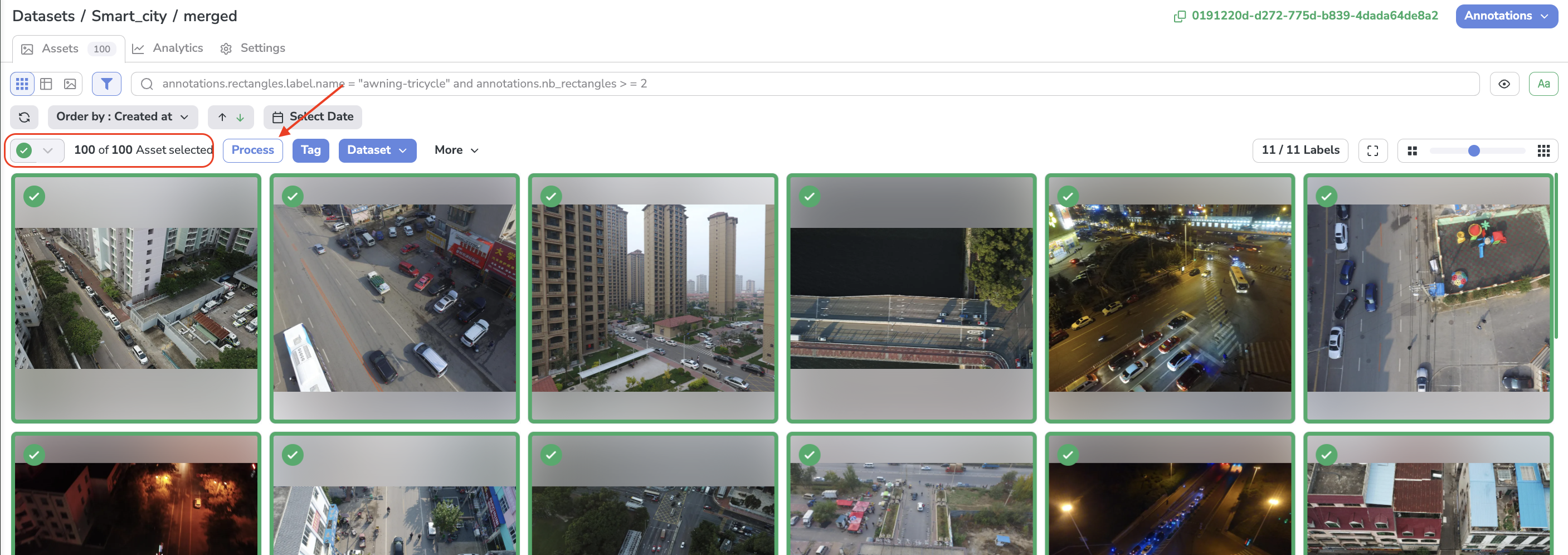
First of all, let's access the DatasetVersion on which the Processing should be applied to.
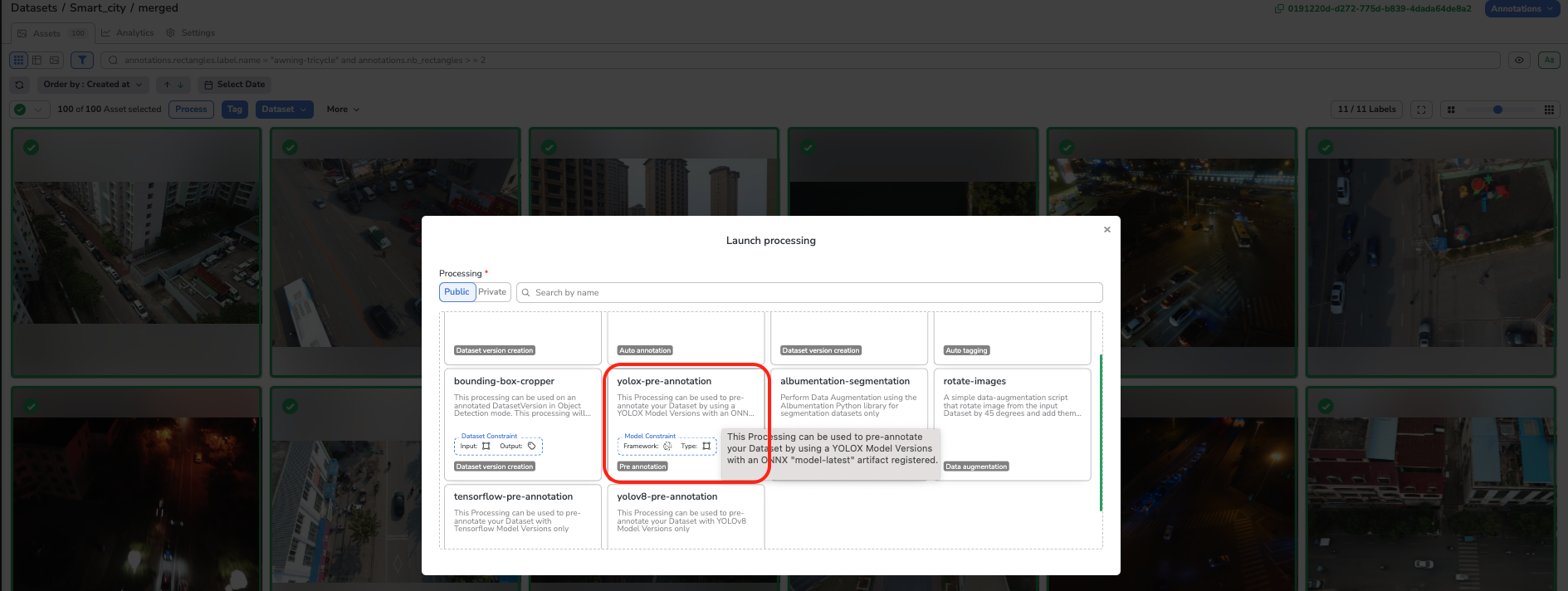
Then, select all the Asset and click on process as shown below:
Process a DatasetVersion
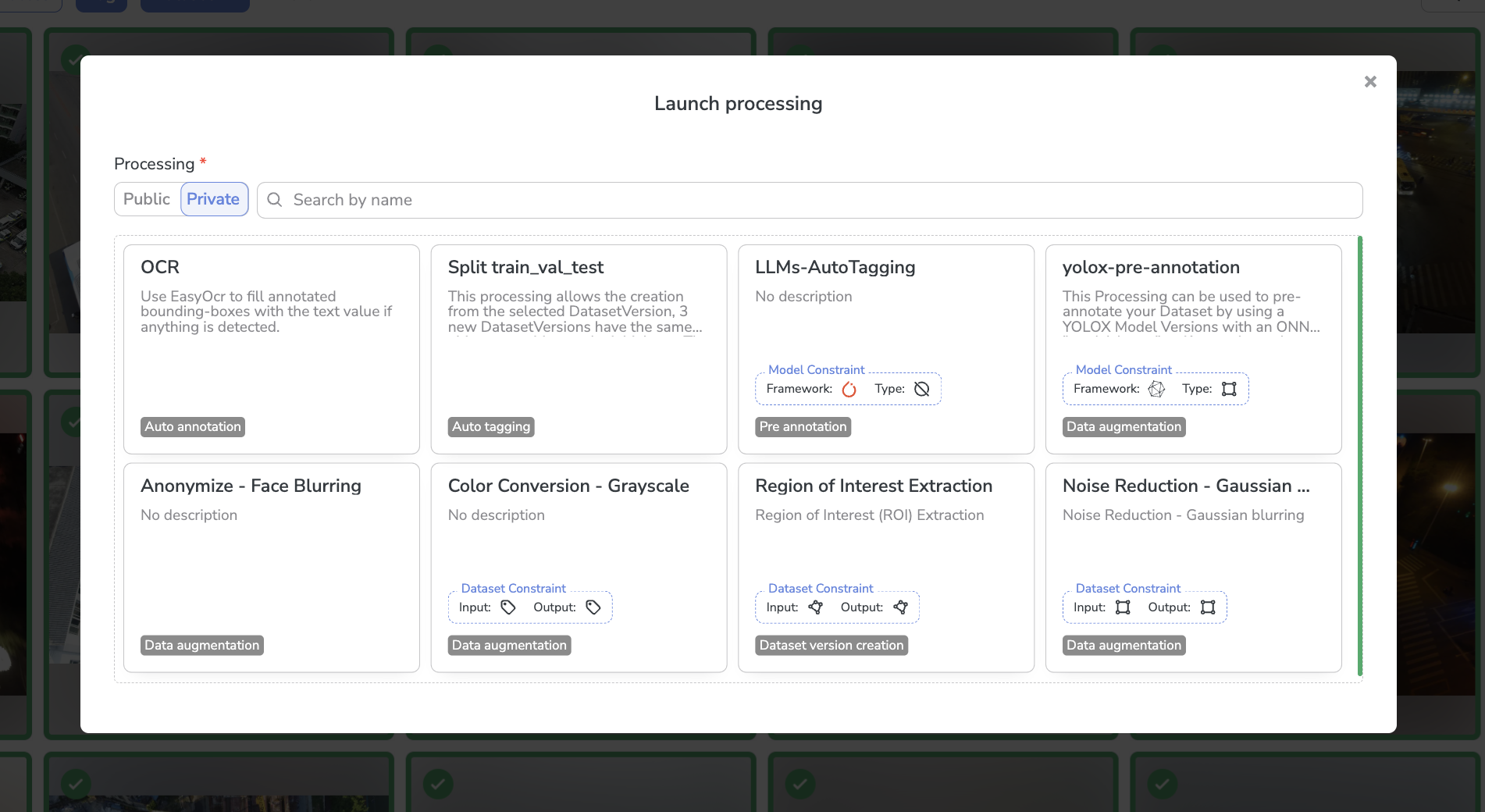
A modal will then open letting you choose among the Public and PrivateProcessing, the one to be executed on the current DatasetVersion.
Select the Processing to run on the DatasetVersion
Depending on the Processing task you might be requested to prompt some inputs to make sure the Processing can be exectued as expected. These inputs can be parameters, the name of the new DatasetVersion or select a ModelVersion for instance.
In the frame of our Pre-Annotation use case, we will select the "yolox-pre-annotation" Processing:
Pre-annotation Processing selection
📘
Read the Processing description
As already mentioned, each Processing has to be used in a specific way, it might require the user to prompt some parameters, ModelVersion or DatasetVersion name. Usually, the Processing description provides all the information to properly configure it and avoid the execution to fall into error.
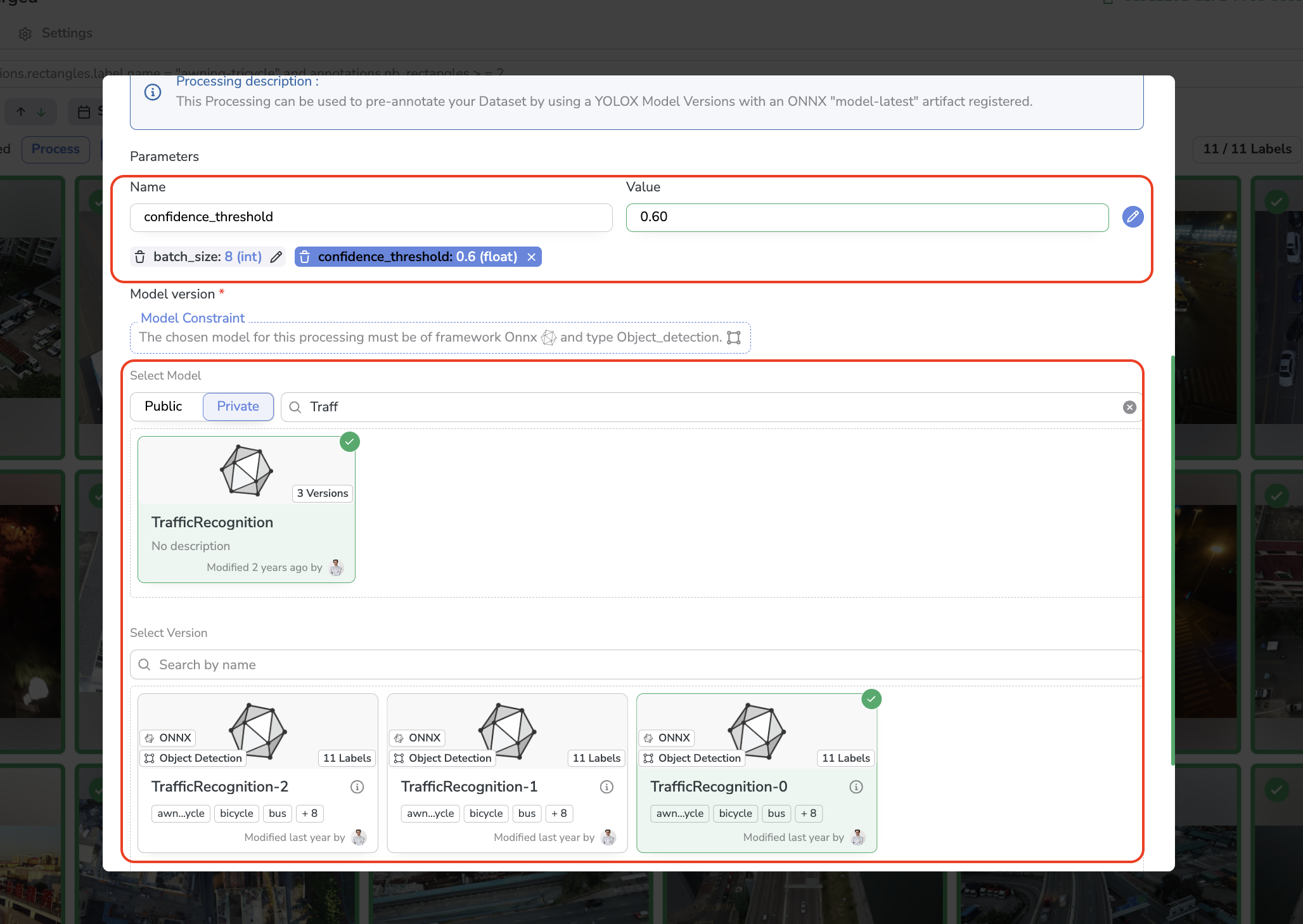
Once the Processing is selected, the modal will extend allowing you to define the execution parameters, in this case, the batch_size & confidence_threshold, and select the ModelVersion that will be used to pre-annotate the current DatasetVersion.
Parameters definition & ModelVersion selection
Please note that a Processing flagged a Pre Annotation for Task can embed constraints on the ModelVersiontype &framework constraints. It means that for example while using a given Pre-annotation Processing, this one can accept only ModelVersion with Object Detection as Detection Type and the TensorFlow as framework, as a consequence only ModelVersion that satisfies these constraints will be available for selection in the Processing selection modal.
📘
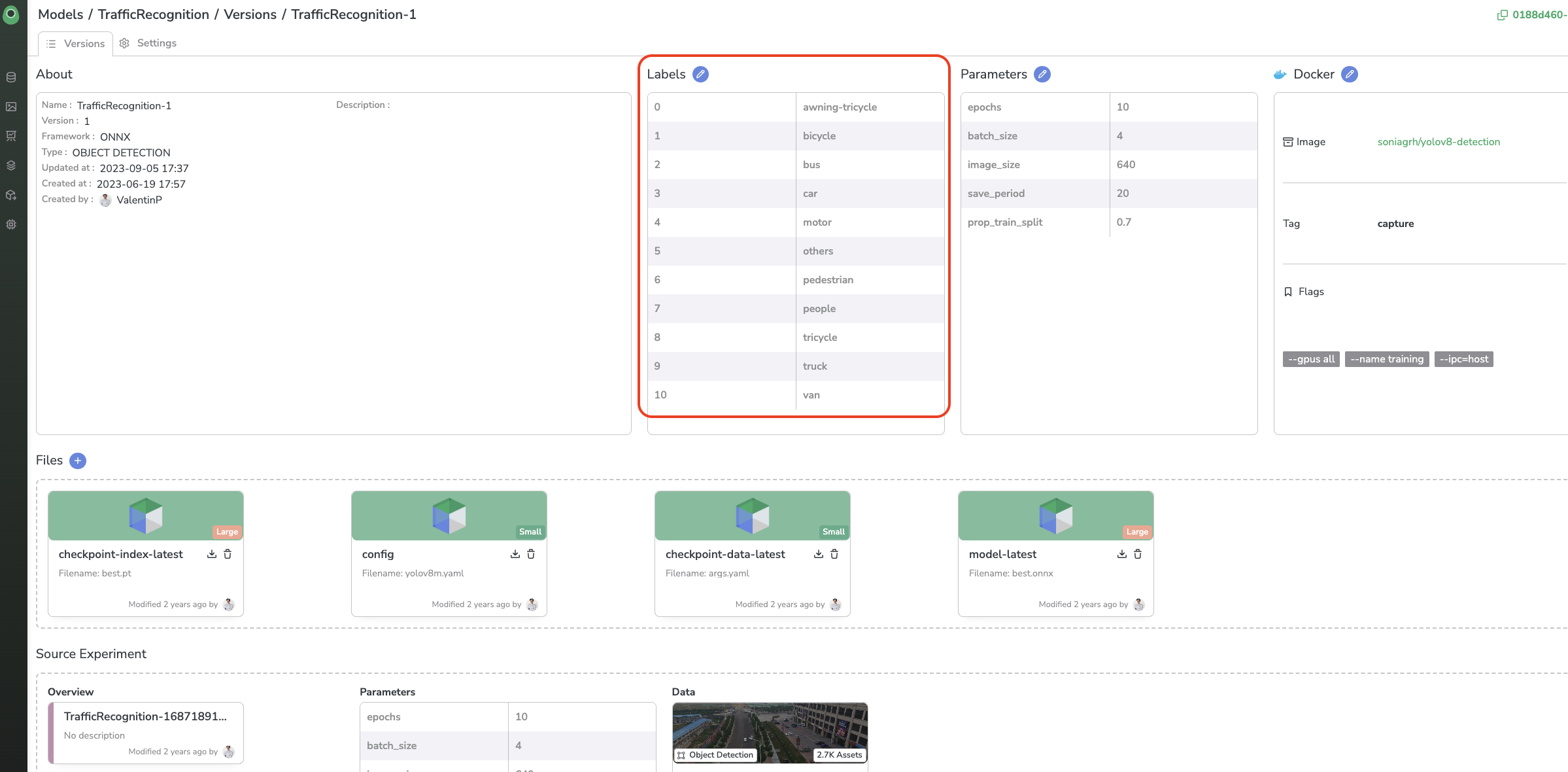
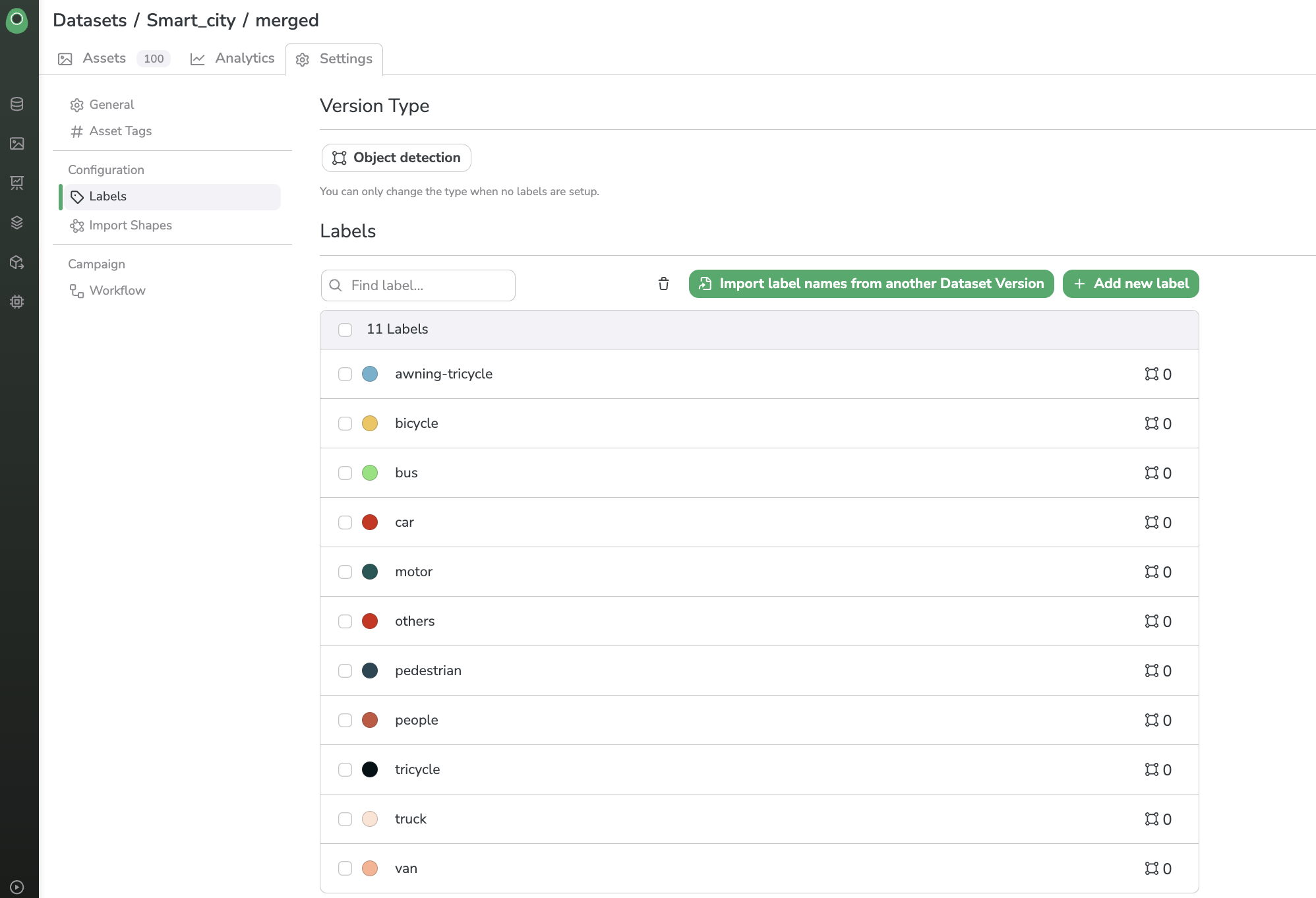
Labelmap correlation
For pre-annotation, you need to ensure that the Labels detected by the ModelVersion selected are already defined as Labels too in the target DatasetVersion.
Labels detected by the selected ModelVersion
Labels defined in the target DatasetVersion
Once everything is properly setup you can launch the Processing execution by clicking on Launch, the Docker image associated will then be executed on Picsellia's infrastructure according to the configuration defined.
To create your own Processing on the Picsellia platform you can rely on the documentation available here.
4. Track the Processing progress
When you launch a Processing, it creates a Job running in the background. You can access the status and many more information about it in the Jobs tab.it should be
Reach Jobs tab
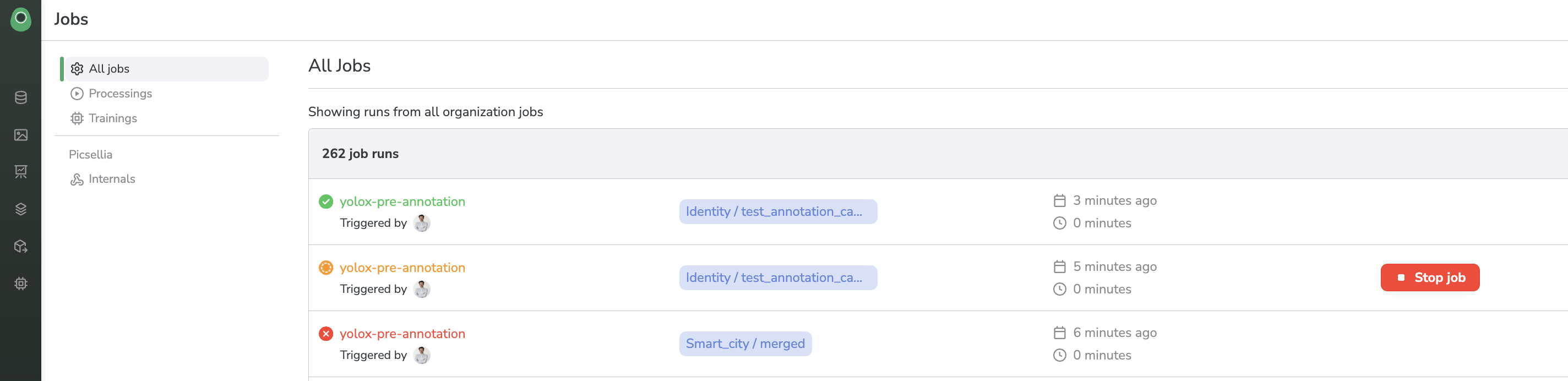
On this page, you can see the history of all the Job that ran or are currently running on your different DatasetVersion.
Jobs overview
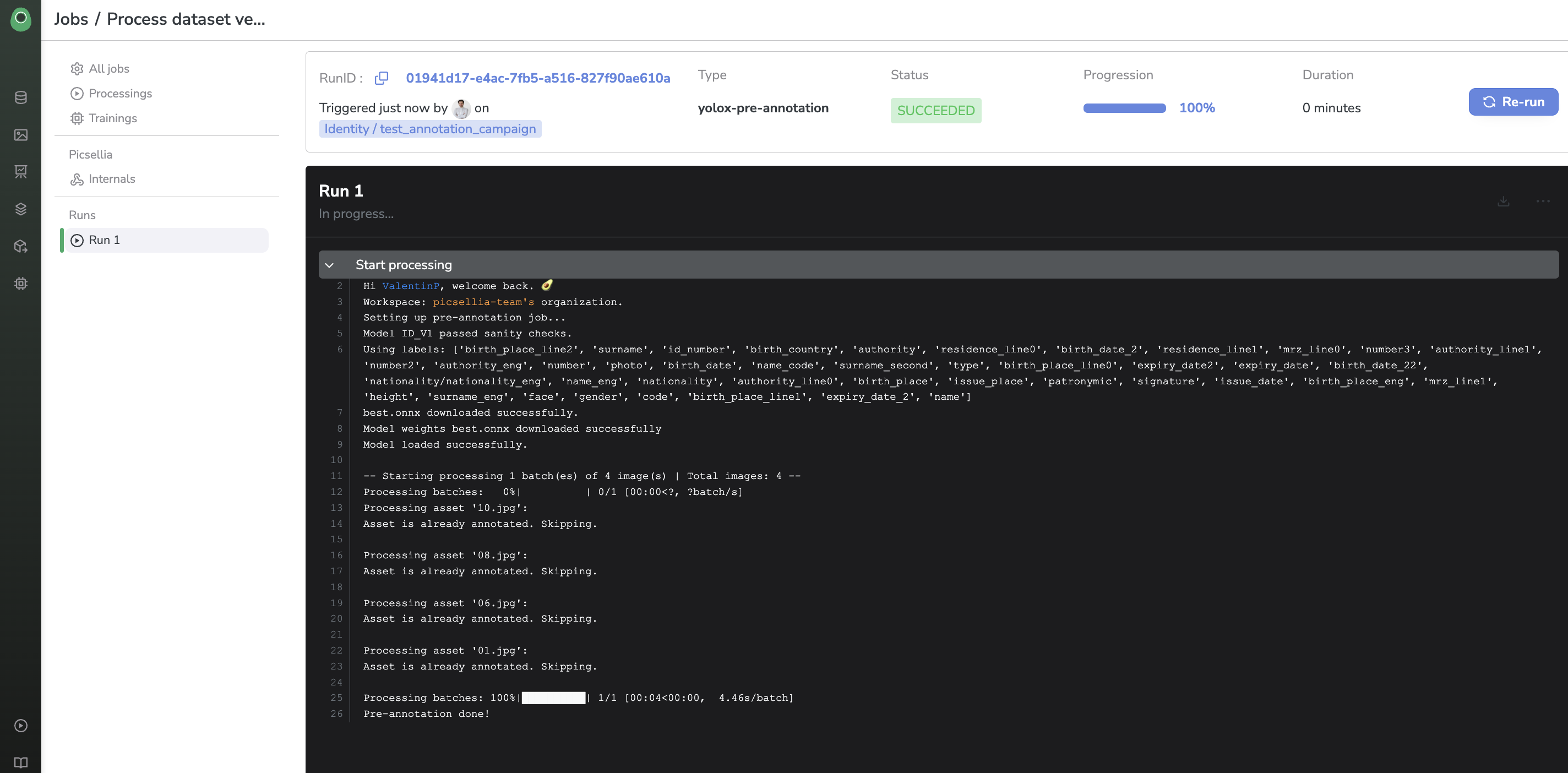
If you just launched a Processing, you should see it at the top of the list. Let's inspect our freshly launched pre-annotation Job.
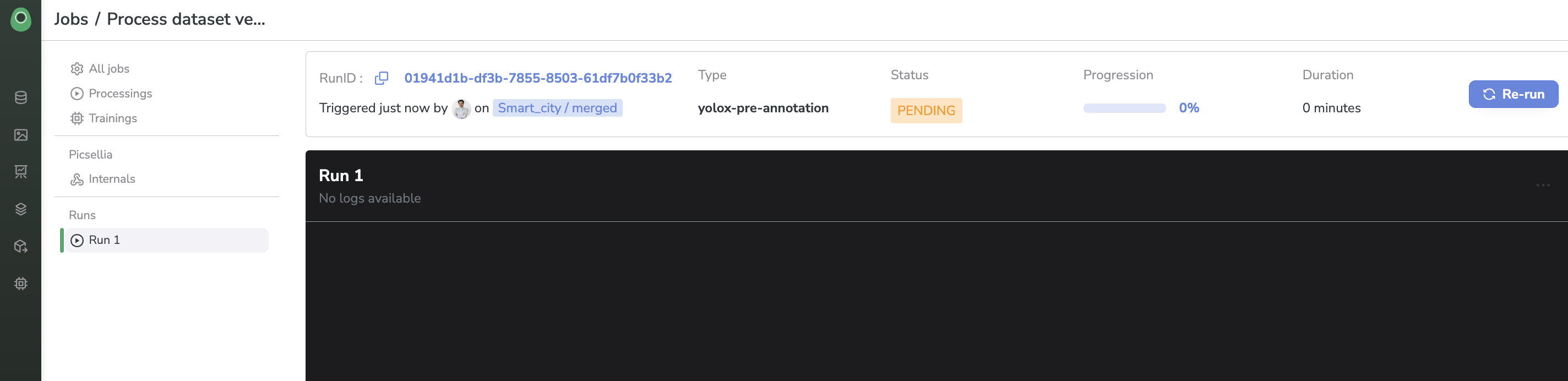
Job logs and status
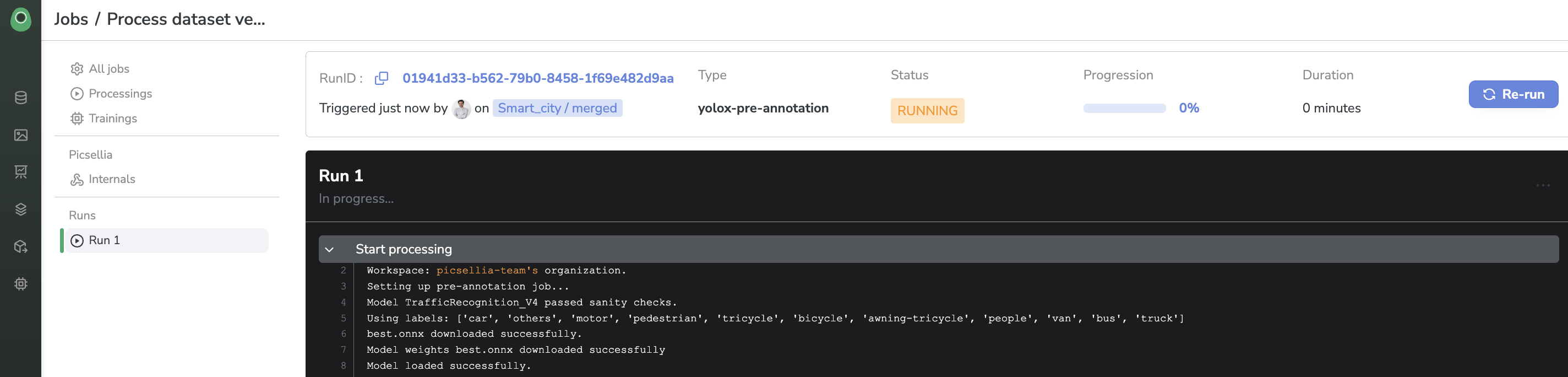
When you launch a Processing, there will be a short moment when the status will be pending. Once your Job has been scheduled (and you start being billed), the status will change to running and you will see some logs being displayed in real-time (those come from the stdout of the server it runs on)
Jobn logs and status
This way, you can really track the progress and the status of your Job and check that everything is going well. In addition, it is a way to keep track of any performed action on a DatasetVersion, such as what Processing has been executed. When ? and by who?
Once your Job is over, you will have access to the full history of logs, and the total running time, and the status will switch to succeeded (or failed, if there were issues at runtime).
Job logs ans status
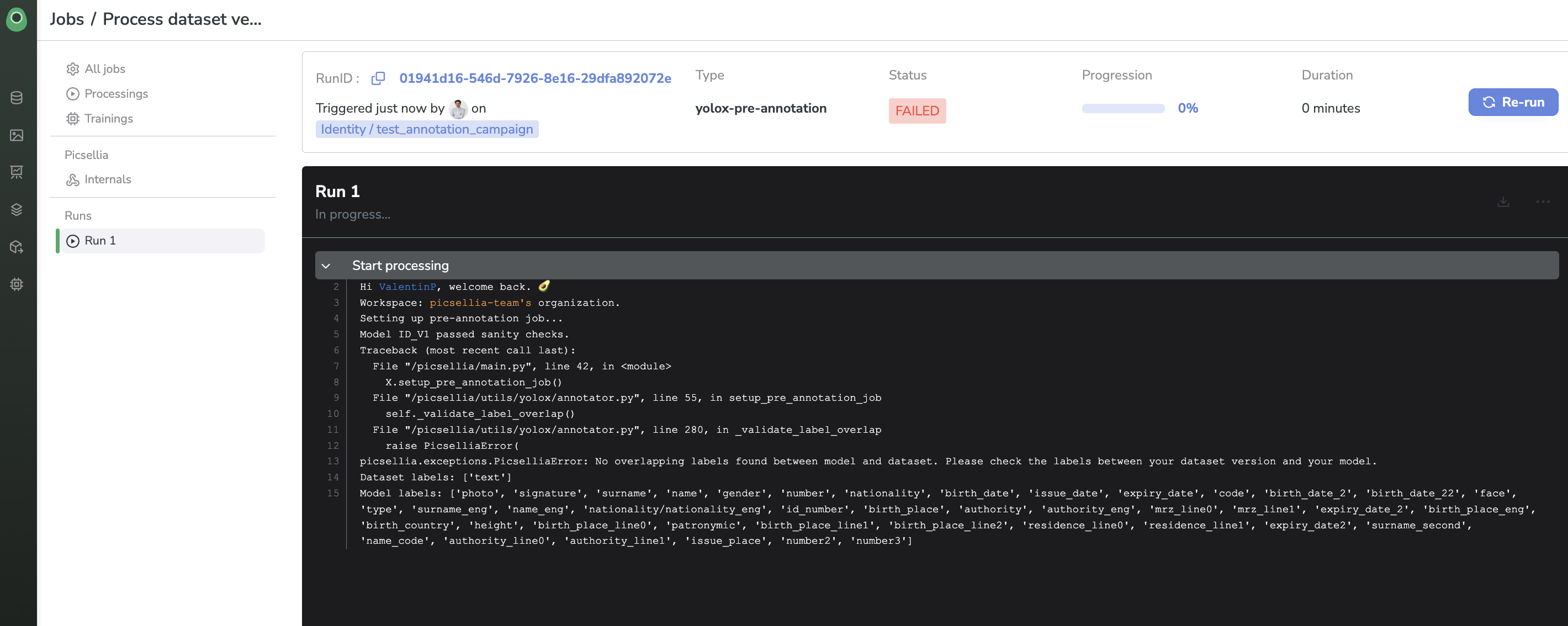
Your Job will fail sometimes, but you'll be able to find the issue thanks to the stack trace in the Job logs:
Job stack trace in case of failure
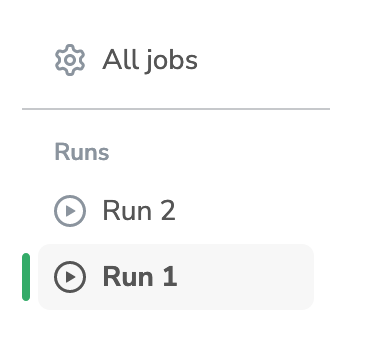
Once you have detected the issue, you have fixed it, and you have updated your Processing's Docker Image, you can click on the Re-run Job button. This will create and launch a second run just like the one on the left of the screen.
Jobruns
🔃
Re-run Job
You can retry your Job as many times as you want, as long as there is no active run (meaning no run in the pending or runningJob)
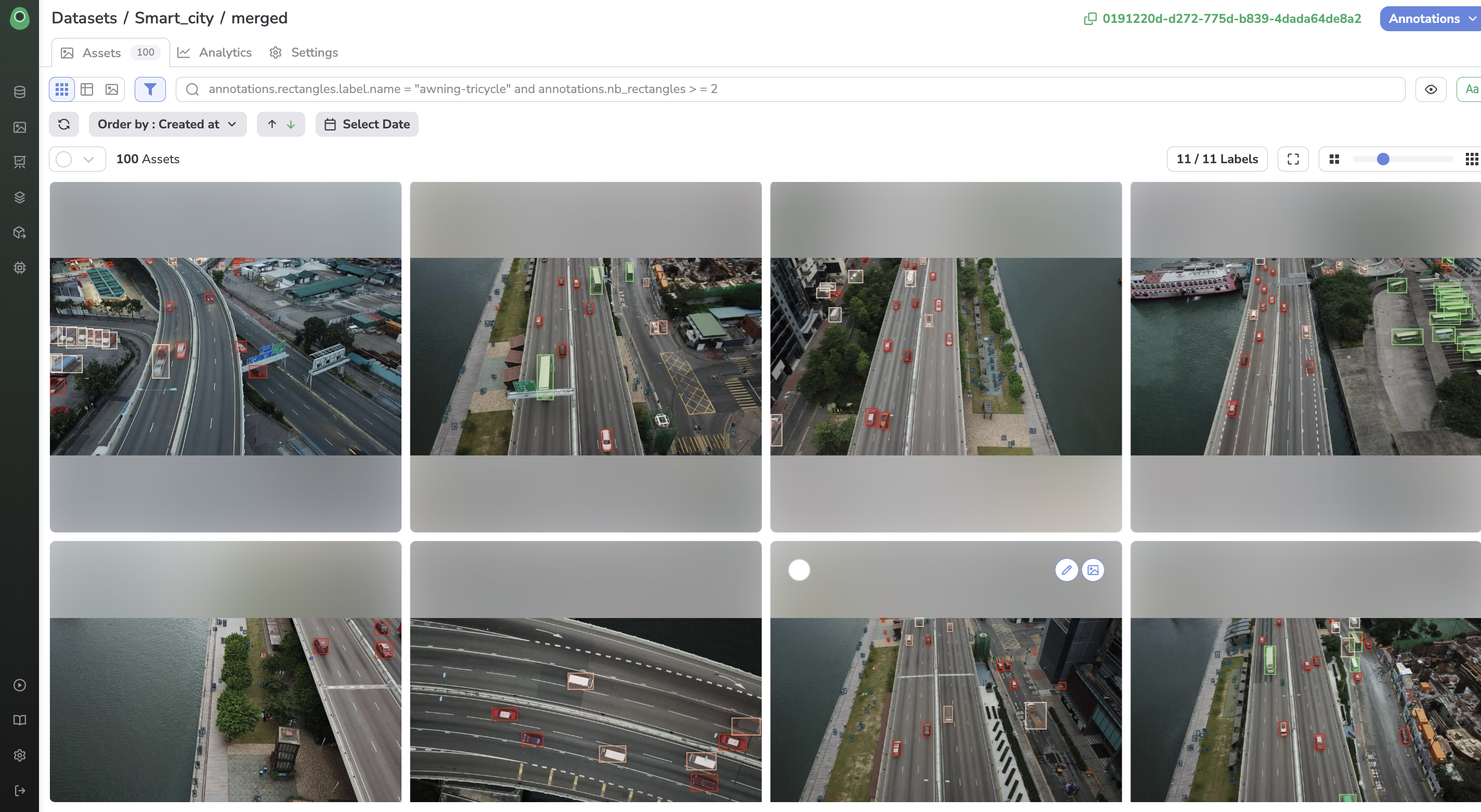
Now that our job has finished, let's have a look at our DatasetVersion! It should be fully annotated with the defined Labels.
Pre-annotated DatasetVersion
Our DatasetVersion has been nicely pre-annotated by our ModelVersion with barely any effort. That's the power of DatasetVersion Processings on Picsellia.
📘
If you want to create your own Processing you can follow this guide.