10. Make predictions
Objectives:
- Let your
ModelVersionmake its firstPrediction - Review
Prediction - Access the metrics computed
- Send reviewed
Predictionto the data pipeline - Observe Continuous training & Continuous deployment
- Assess that the freshly trained model is over-performing the initial one
1. Make Prediction with your deployed ModelVersion
Prediction with your deployed ModelVersionA. If your model is served on Picsellia's infrastructure
Now that our deployment is fully set up, we can perform inference on the model to get predictions.
This part can only be done using the Python SDK, so we strongly recommend you rely on the associated documentation available here.
B. If you want to serve your model with your own infra
If you want your model to be served by your own infrastructure, you can follow this recipe to store the results of the inferences done by your model and leverage the "Monitoring Dashboard" remotely.
2. Review predictions
Once the prediction is done, the monitoring dashboard of the deployment should be updated. The metrics are updated in real time according to the predictions made by the model.
Unsupervised metrics are computer only if "training data" has been activated
The “Predictions” view allows you to visualize and browse among predictions done until now by the model. Once again, you can leverage the search bar to filter among predictions. For instance, you can retrieve inferences that have been human-reviewed, all the inferences with more than X bounding boxes on them, or predictions that have no "car" labels on them.
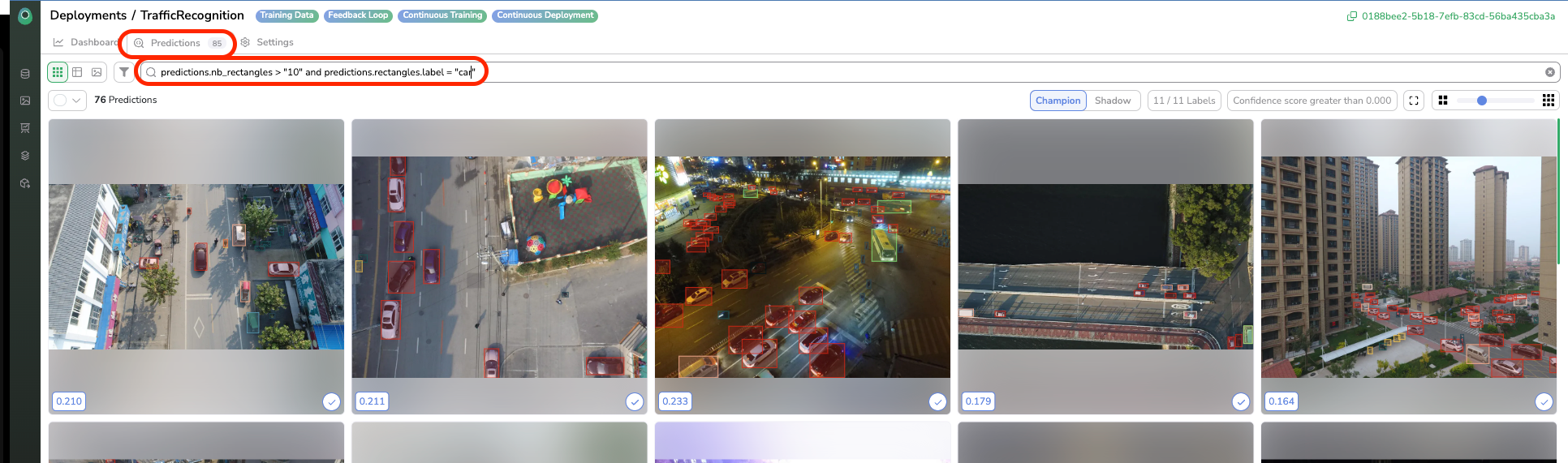
For each Prediction, you have got the possibility to open the Prediction Review tool by clicking on Review. After landing on the tool, you can review the Prediction done by the ModelVersion (i.e accept it or modify it).
The Prediction Review tool looks like the Annotation tool, it allows you to filter the confidence rate and modify/add/delete Predictions. Once the Prediction has been humanly reviewed, you can click on Review.
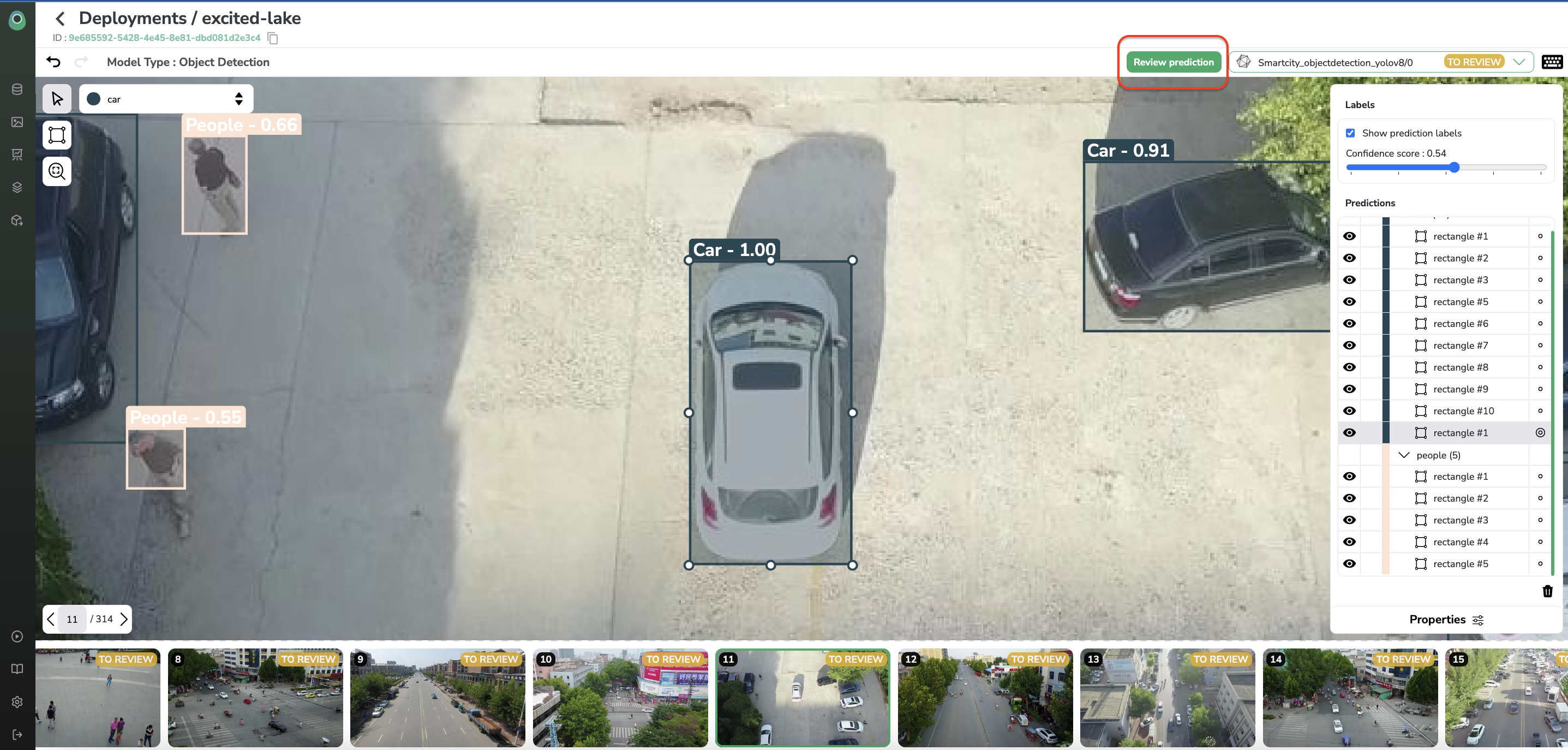
Identify high quality images to enrich yourDatasetVersion
Predictionscan be sorted by outlier score, it allows you know whichPredictionare the most relevant to review and add in the training set (through Feedback Loop) in order to prevent data drift.
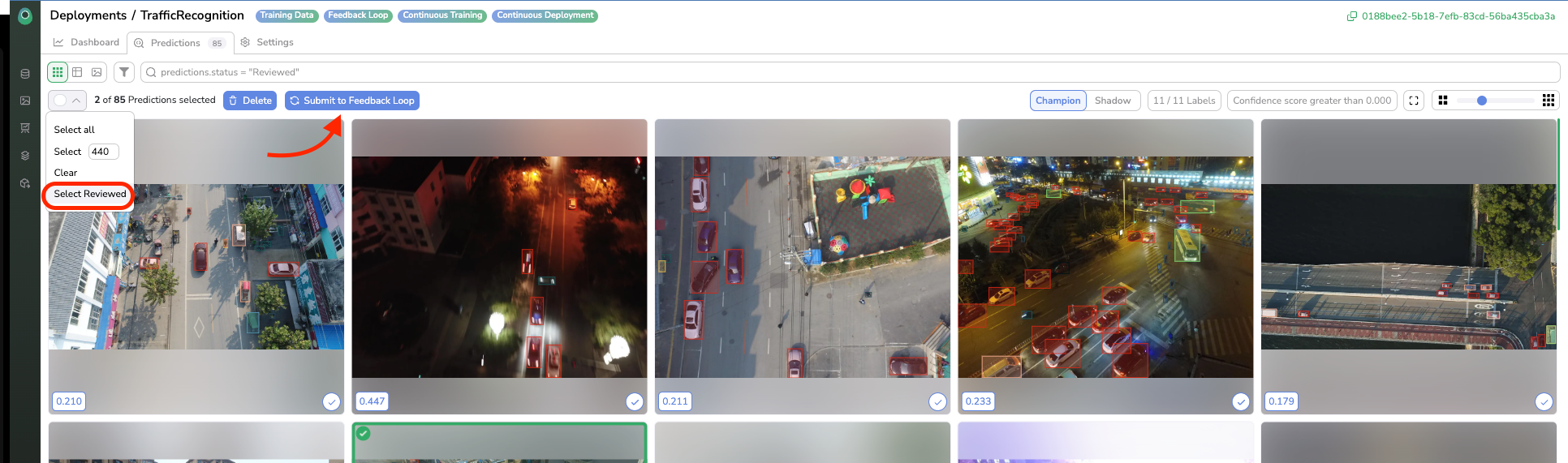
Once reviewed, the status of the predictions is Reviewed, which means that the Prediction has been approved/corrected by a human, tho the review is used to compute supervised metrics on the Monitoring Dashboard and it also means that the Prediction is ready to be added in the Feedback Loop (i.e DatasetVersiondefined in the Settings tab).
To do it, back to the Predictions tab, now each Prediction in Reviewed status can be selected, then the selection of Reviewed Prediction can be submitted to the Feedback Loop by clicking of Submit to feedback loop button (here is the link to related documentation).
As soon as done, the Prediction goes into Submitted status, and the reviewed Prediction is added to the selected DatasetVersion.
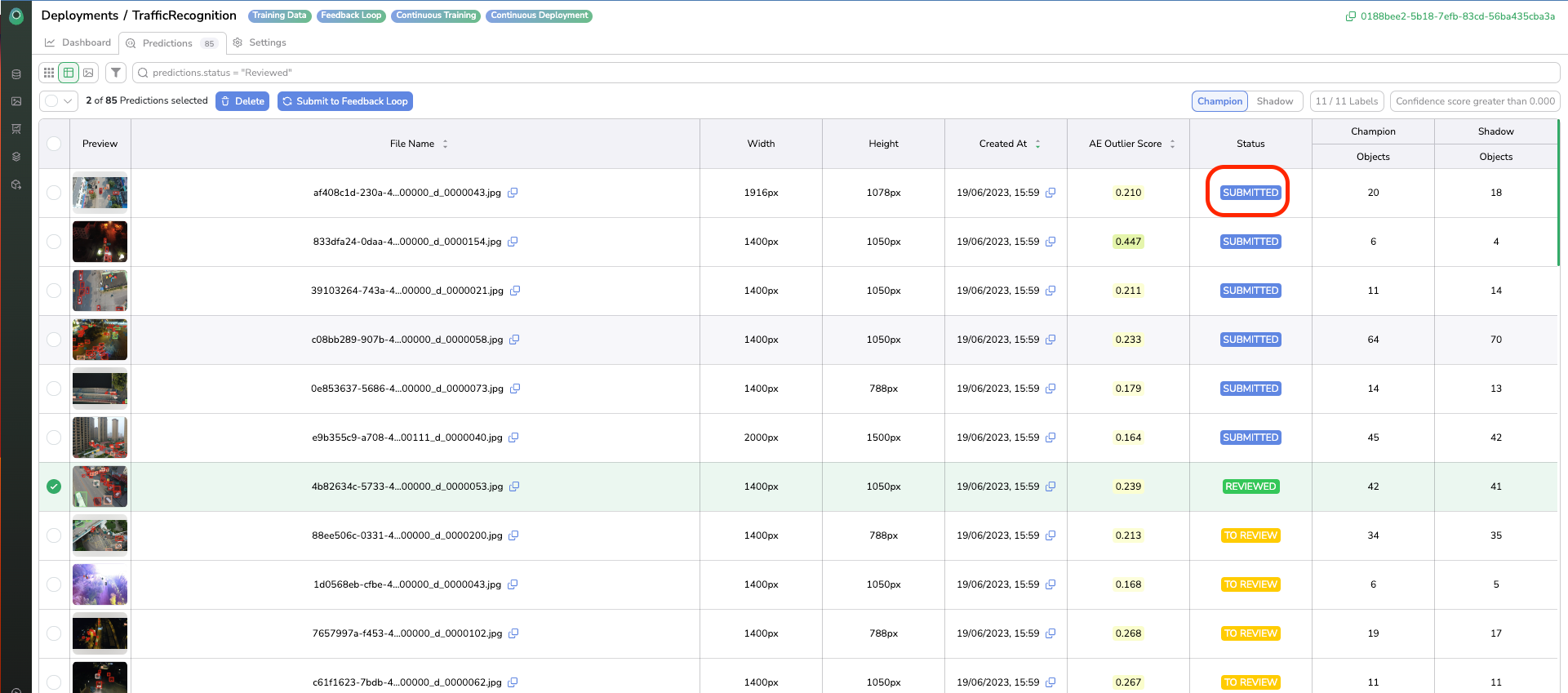
Table and Details views are also available in the Predictions overview allowing you to accessPredictionmetadata for instance.
When the number of images submitted to the Feedback Loop reaches the threshold defined the in the Continuous Trainingpart of the settings, a new Experiment is automatically launched on the related Project with the predefined parameters. By the way, training automatically launched via Continuous Training can be recognized with the timestamp at the end of the Experiment name.
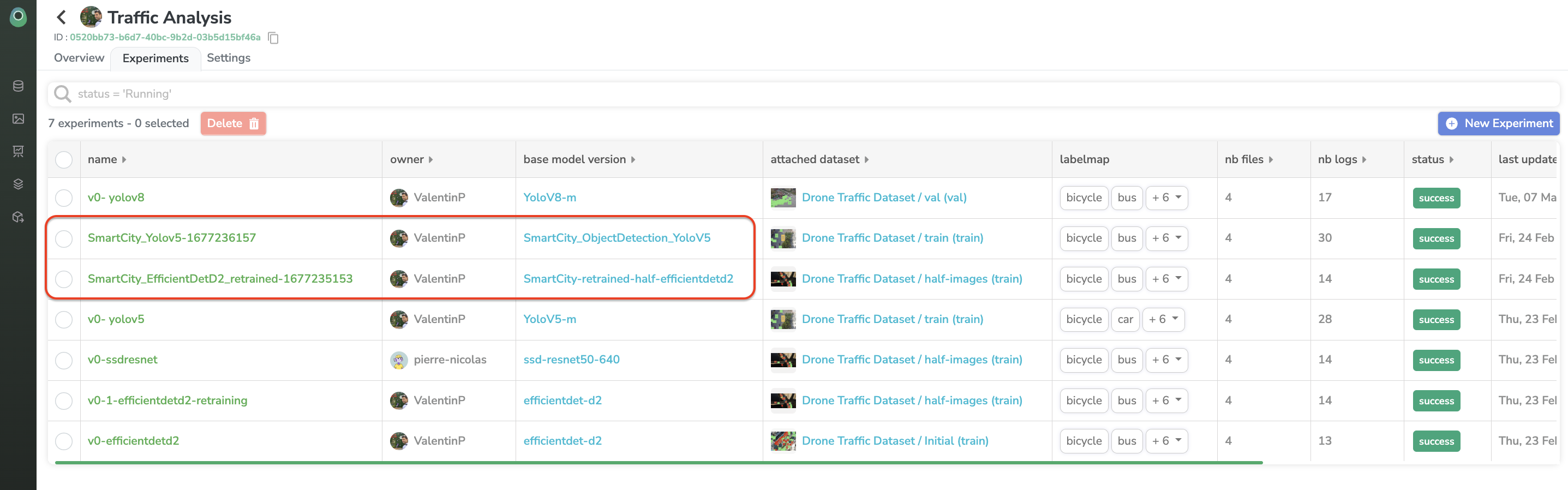
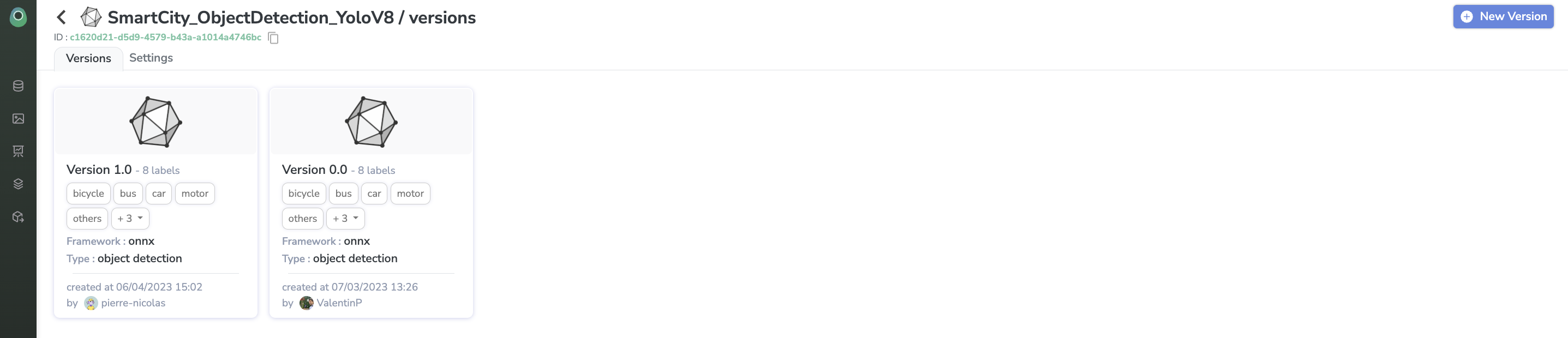
Once the Experiment is over, it will be exported as a new version of the currently deployed ModelVersion and deployed according to the Continuous Deployment policy.
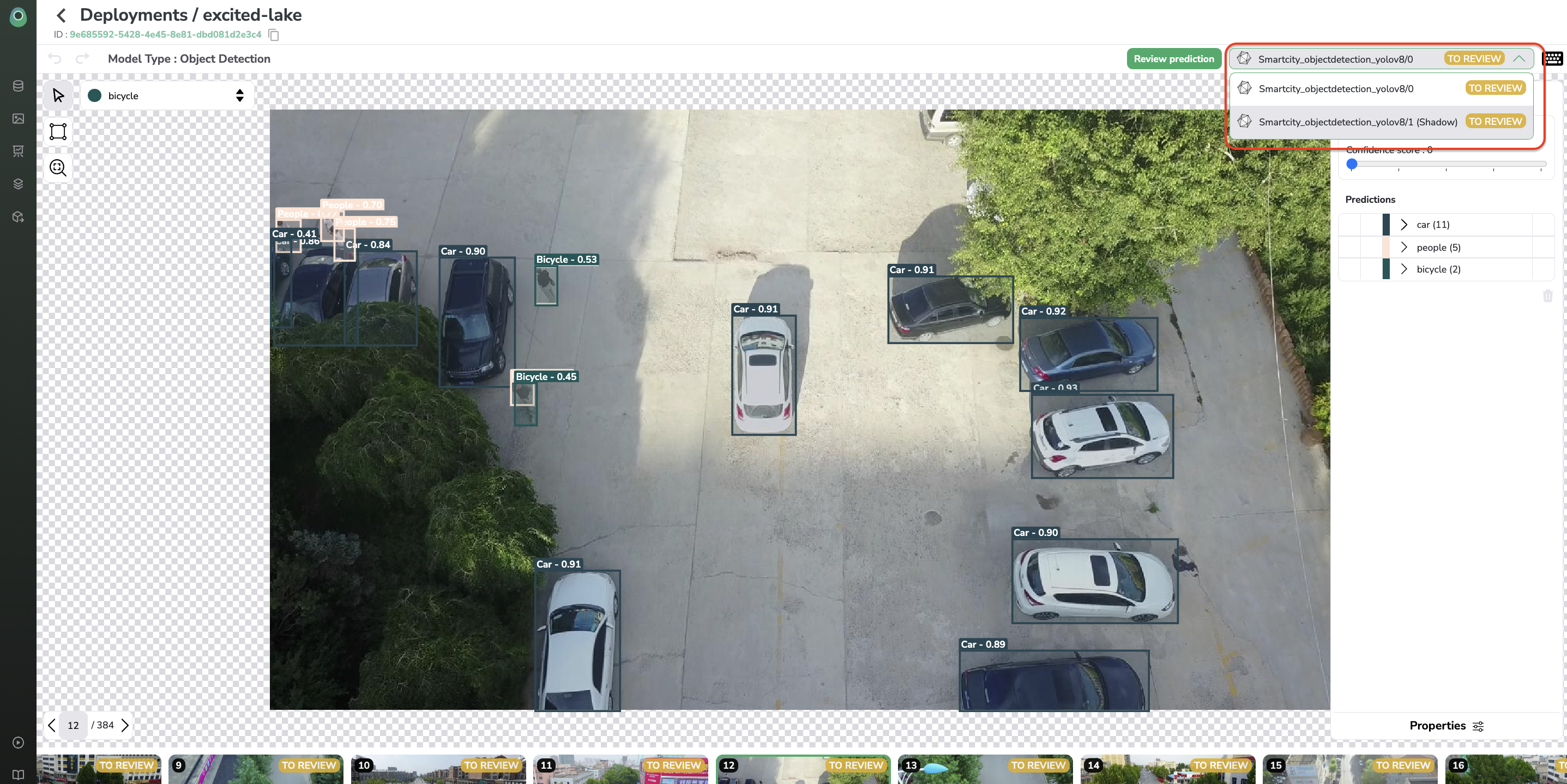
In the case of Shadow Deployment, for further predictions, you can switch between Champion model predictionand Shadow model prediction in the top right corner of the Prediction Review tool:
Updated about 1 year ago