6. Import your Annotations
Objectives:
- Visualize the assets of your
DatasetVersion - Import your
Annotation - Use the integrated Annotation tool
- Browse among
Assetor structure them of theDatasetVersion - Download
Asset&Annotation - Operate your
DataProcessing - Assess the quality of your
DatasetVersion
1. Visualize a DatasetVersion
DatasetVersionYou will access the Assets view by clicking on the DatasetVersion.
First, the Assets view offers the possibility to visualize your DatasetVersion and browse it among its Asset. Each DatasetVersion also embeds its own tagging system (independent from the Datalake tagging system) allowing you to structure your DatasetVersion as you wish using AssetTag.
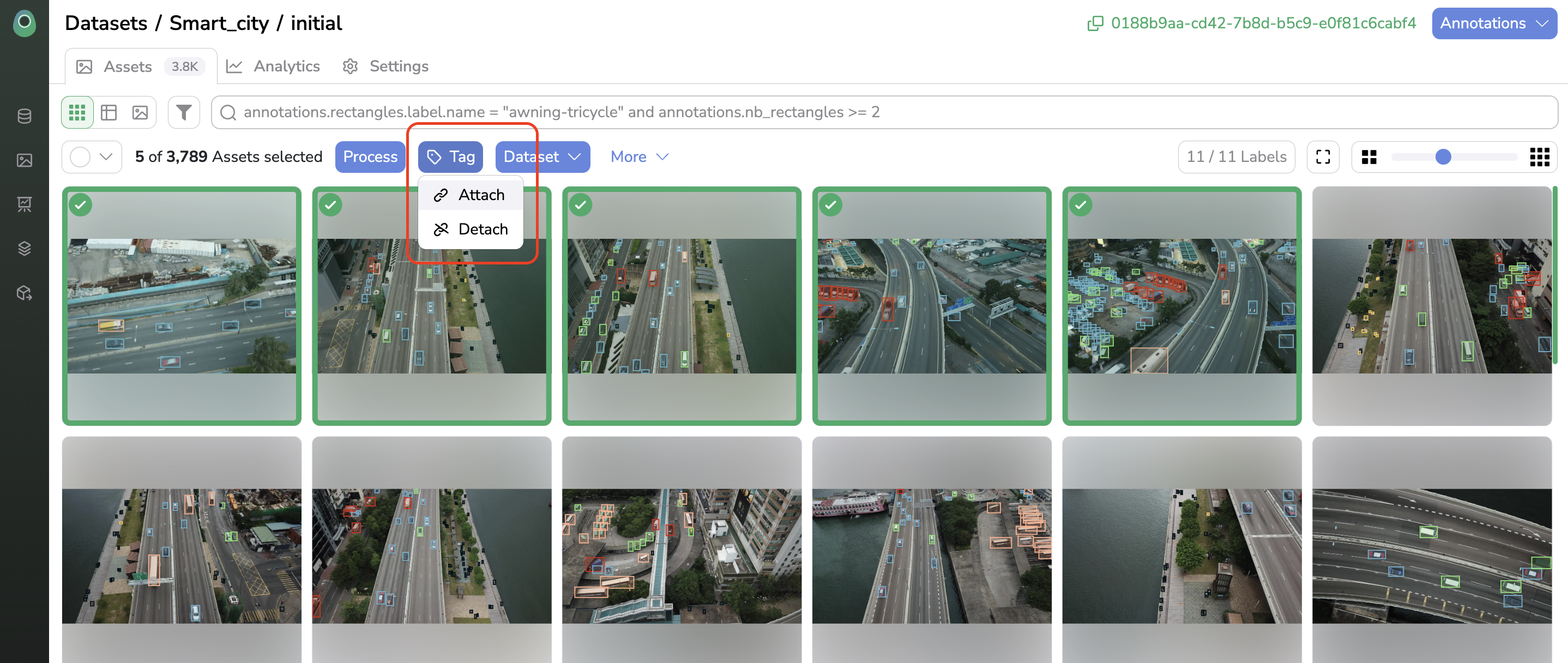
At this step, theDatasetVersion should be free of Annotation.
2. Import your Annotation and/or use the integrated Annotation tool
Annotation and/or use the integrated Annotation toolIf you have the Annotation already available locally, you can import them directly into yourDatasetVersion, nevertheless, they must be in COCO, YOLO, PascalVOC or ViaLabel format. To do so, press the Annotation button at the top right corner and select Import annotations. Then, follow the modal’s instructions to upload the Annotation file.
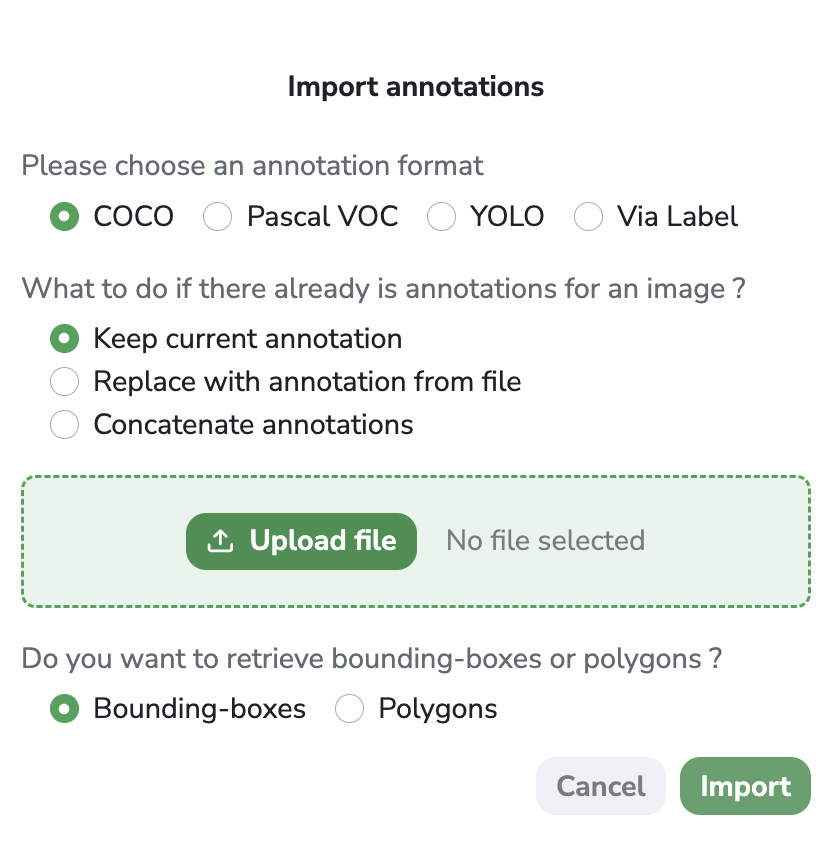
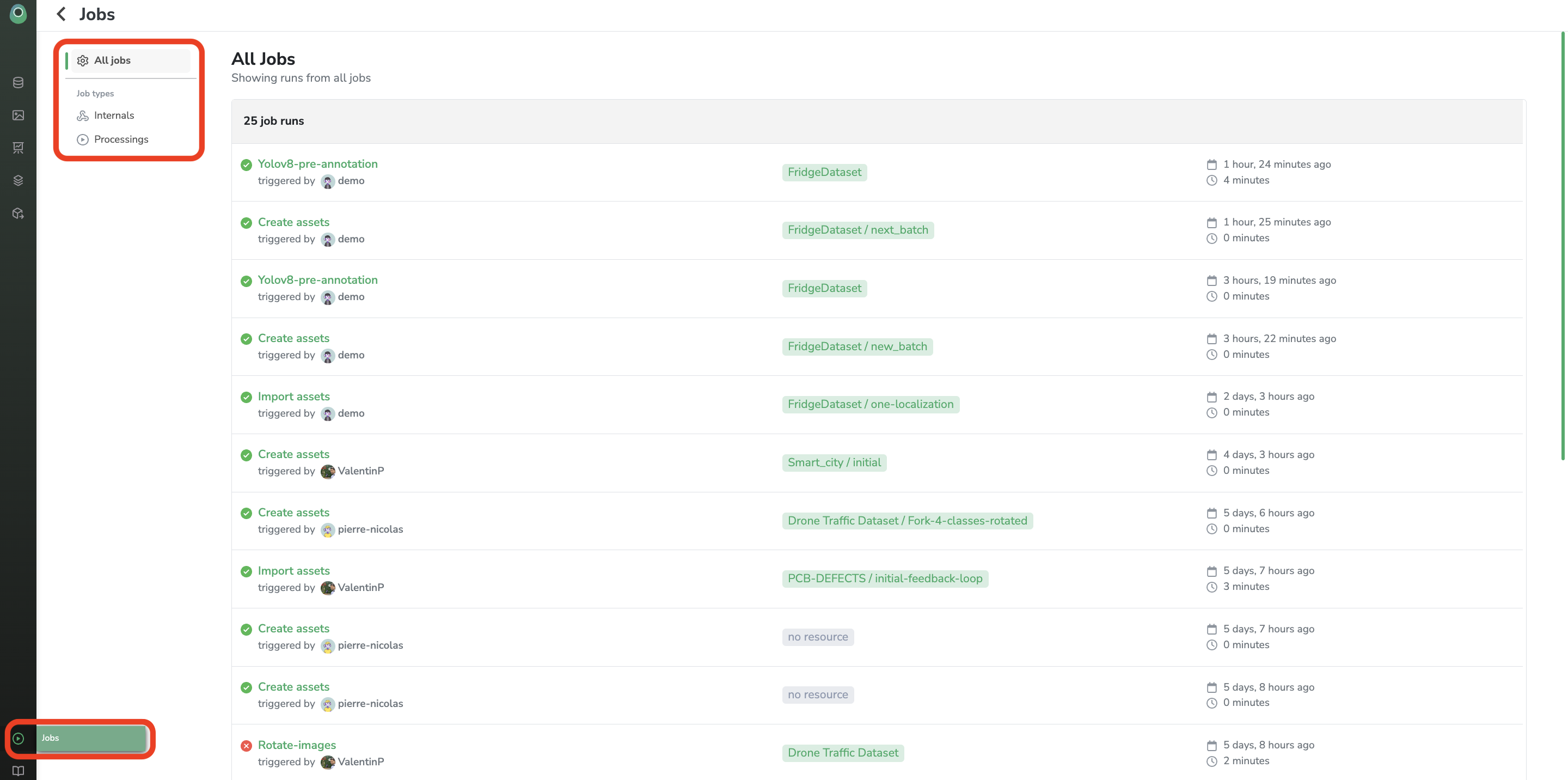
The Detection Type, the Label, and the Annotation will automatically be set up during the Annotation import process. This import task is asynchronous, so you can follow its completion in the Jobs view:
Any Picsellia asynchronous task (
Annotationimport,DatasetVersioncreation..) can be tracked from this Internal jobs overview:
To do it with the SDK:
Even with imported Annotation you can still modify it using the PicselliaAnnotation tool. To do it, you should go to any Asset from the DatasetVersion and select the Annotate button. Then the Annotation tool will open and you can remove, add or modify any Annotation from your DatasetVersion, more details about the Annotationimport are available here.
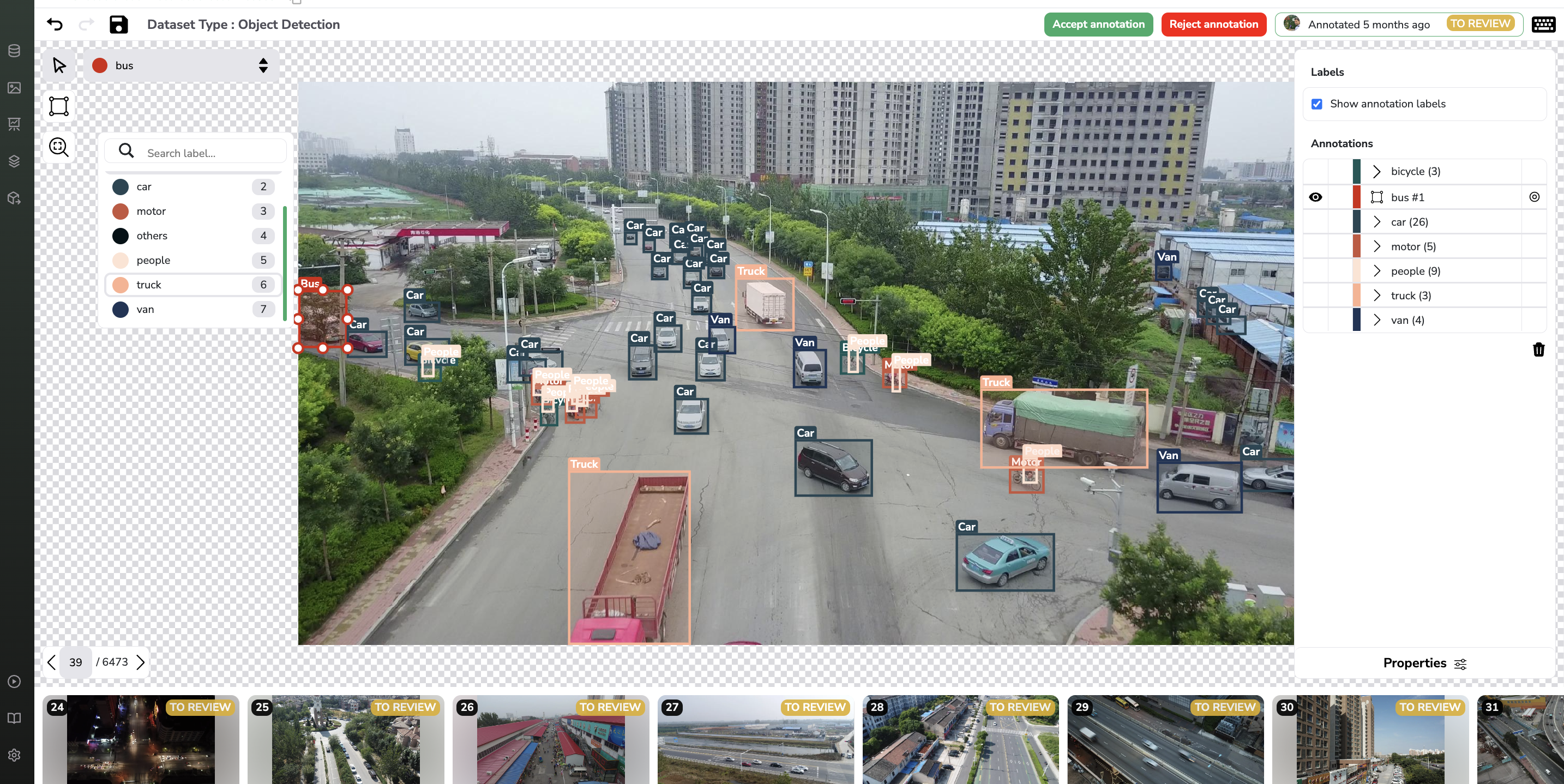
A. If you do not have an Annotation file already
If your DatasetVersion needs to be manually annotated, you can use the Annotation tool of Picsellia to annotate your whole DatasetVersion from scratch.
To do it, you need first to go to the Settings part of your DatasetVersion and define in theLabels tab the Detection Type and the associatedLabels (e.g classes).
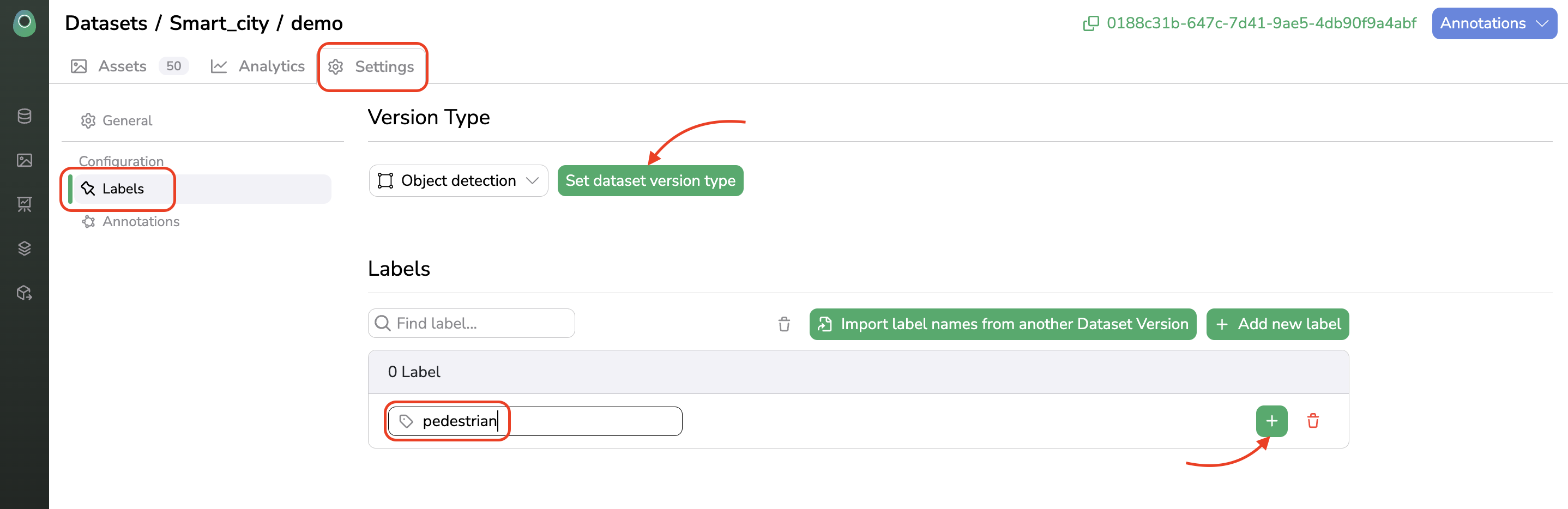
Once done you can go back to the Assets view and start to annotate the Asset. More details about the Annotation tool are available here.
B. In the case of a Classification
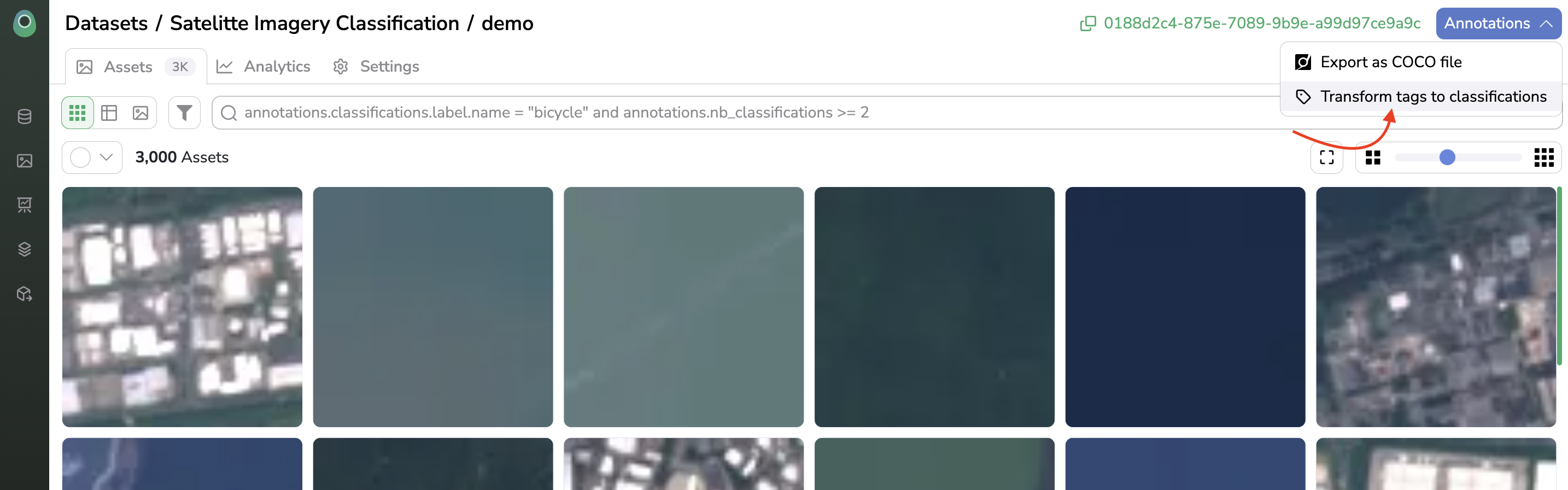
In case you want to develop a Classification ModelVersion, you can use a handy feature called Transform tags to classifications. A prerequisite is that you have uploaded each Data with the DataTag related to its Annotation. Be careful, for this manipulation each Data uploaded must have only one DataTag at the Datalake level which is supposed to be the annotation later in the DatasetVersion. Then after the DatasetVersion creation, in the Settings tab, you need to set up the DatasetVersion as Classification.
Once done, back in the Assets view, by clicking the Annotations button you should see Transform tags to classifications, click on it, and the Labels will be automatically created and the Asset classified based on the DataTagof the related Data. Please note that this operation can take a few minutes but is done asynchronously so you can keep working on Picsellia in the meantime.
Picsellia offers you the opportunity to run Processings on yourDatasetVersionProcessings are the perfect tool to apply specific treatments to your
DatasetVersionsuch as Data augmentation or pre-annotation. Here you can know more about Processings.
3. Browse among Asset
AssetNow that the DatasetVersion is fully annotated, you can browse among itsAsset thanks to the Search Bar. Do not hesitate to use auto completion to get what are the Asset properties you can filter on.
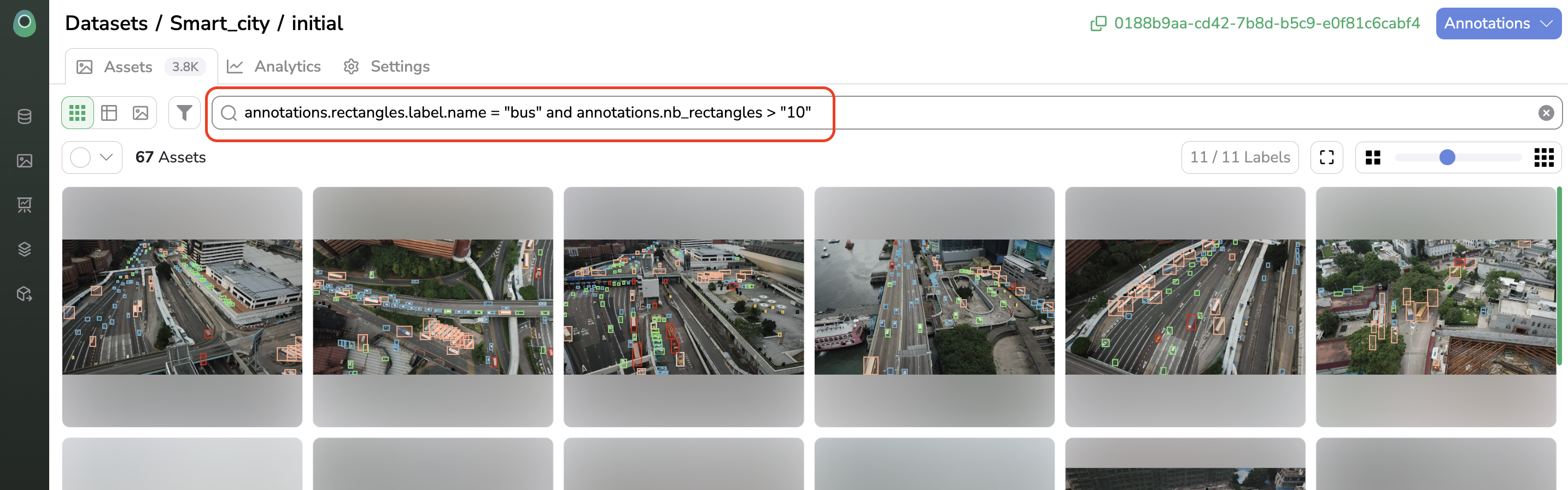
You can even retrieve
Dataproperties from theDatasetVersionsearch bar typing "data.***"
4. Ensure DatasetVersion quality
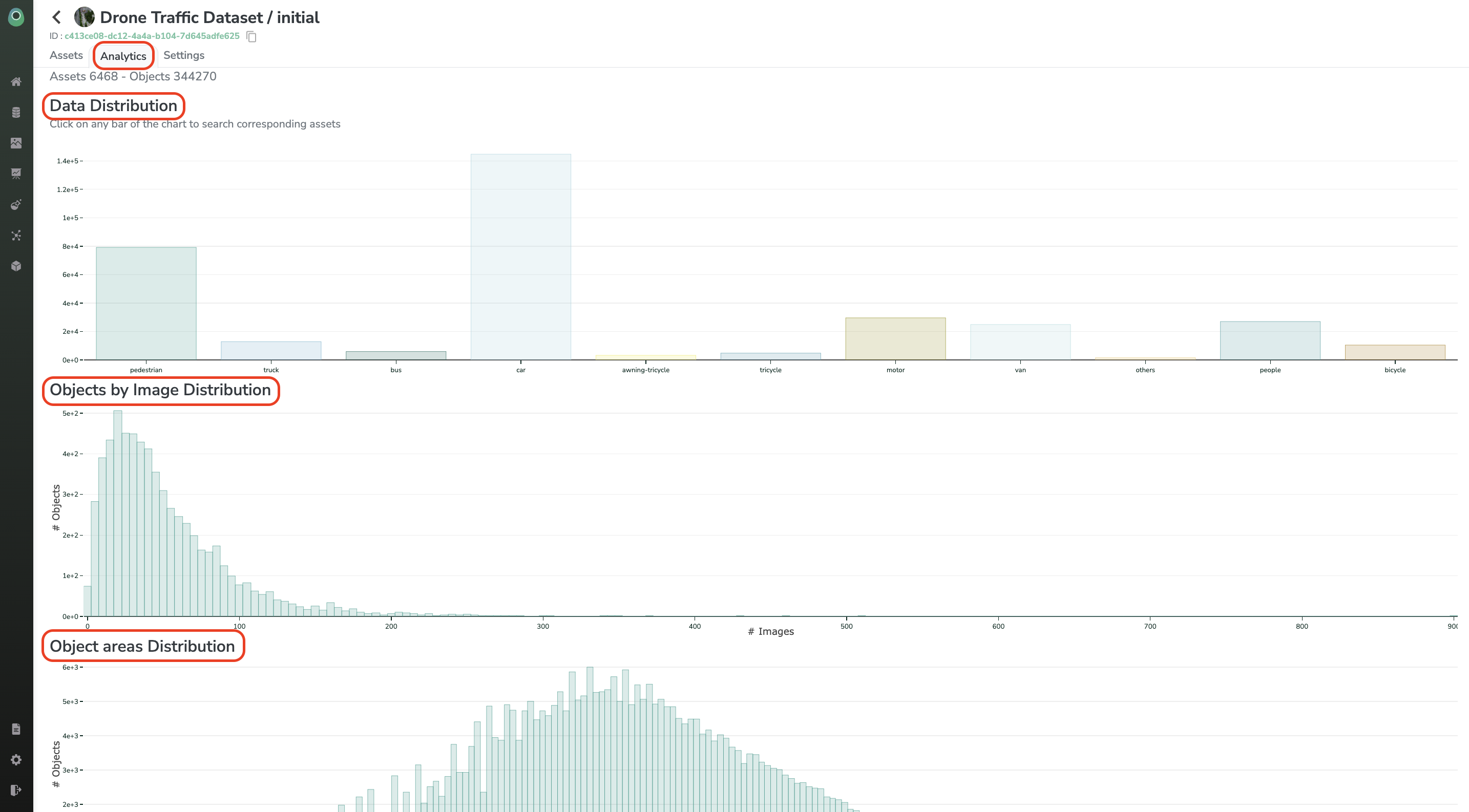
DatasetVersion qualityOnce the DatasetVersion is fully annotated, you can leverage themetrics tab to ensure your DatasetVersion is fitting your needs. As DatasetVersion quality is key to ensuring Model performances, those metrics should be used to assess DatasetVersion quality, diversity, and balancing:
Updated about 1 year ago