9. Deploy a ModelVersion and set the Data Pipeline up
Objectives:
- Deploy your
DatasetVersion - Set your Data Pipeline up
- Access your Model Monitoring Dashboard
1. Deploy your ModelVersion
ModelVersionFrom the Model Version view, you can now deploy your ModelVersion to make it able to perform Prediction by clicking on Deploy.
The Deployment can be done on the OVH infrastructure provided by Picsellia or directly on your own infrastructure.
While deploying the ModelVersion, a confidence threshold will be asked, be advised that any Shape with a confidence score lower than this threshold won't be taken into account, as a consequence we advise you to put a low threshold first and adjust it later in the Settings of the Deployment.
Once the confidence threshold is defined, the ModelVersion is deployed. You can access all your Deployment from the Deployment view and select any of them to access its Monitoring Dashboard.

2. Monitoring Dashboard
The Monitoring Dashboard of a Deployment view allows you to access many metrics related to your ModelVersion performances such as latency, heat map, KS Drift, Outlier score, mAP, and global distribution…. By the way, you can find details about them over there.
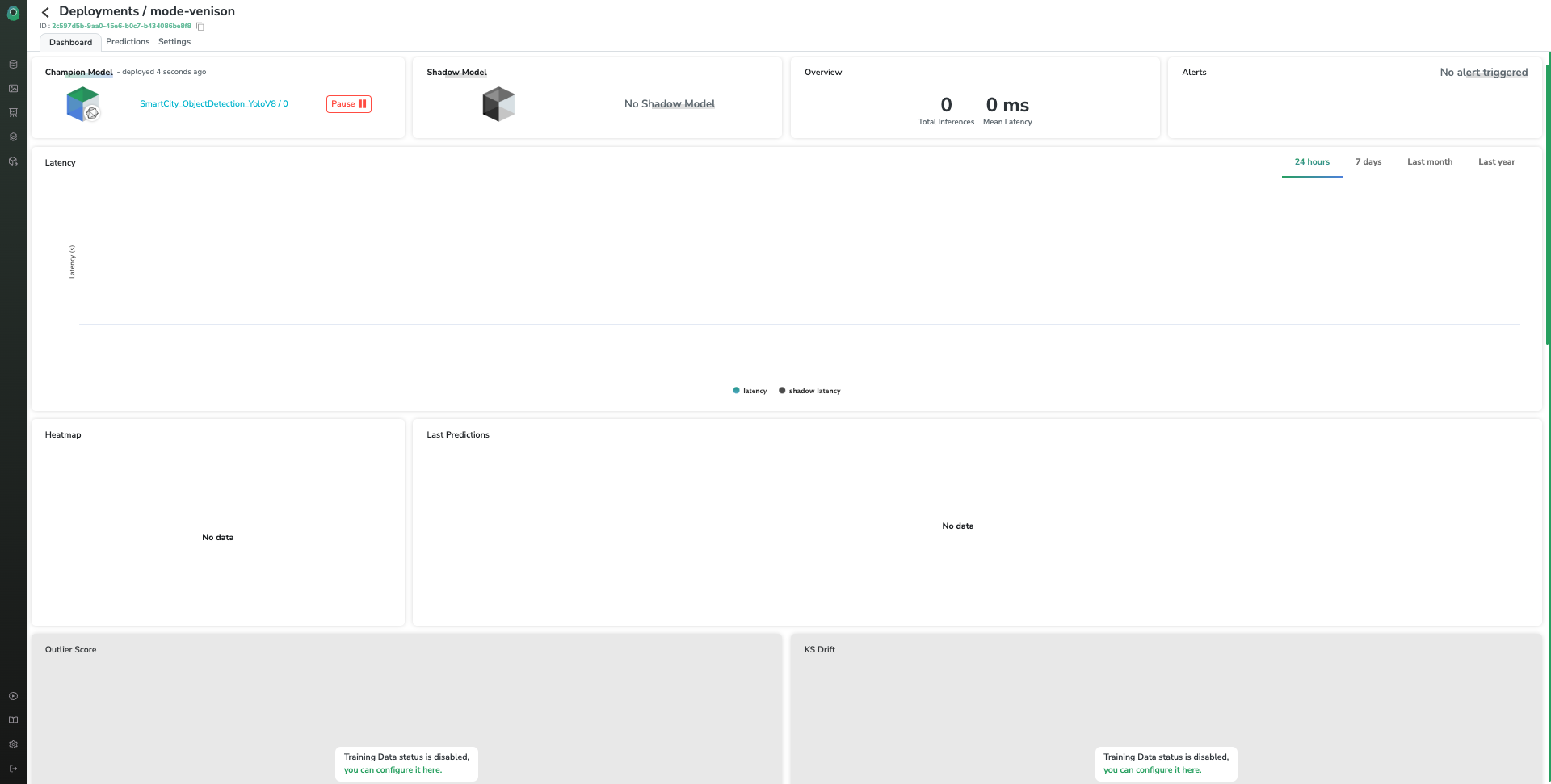
Right after the ModelVersion deployment, those metrics are supposed to be empty until Prediction are done by our ModelVersion.
3. Set the Data Pipeline up
The main idea of this Data Pipeline is to ensure that the ModelVersion is always improving by leveraging human-reviewed production Data.
As a consequence, before making a Prediction, it is useful to set up the following things in the Settings tab:
- The training Data indicates the
DatasetVersionused to train the deployedModelVersionso supervised metrics such as KS Drift can be computed. If you pushed and deployed aModelVersionon Picsellia without the Training Data, it's unnecessary to do it, but be advised that unsupervised metrics will not be computed. - The feedback loop is a way to leverage
Datacoming from the production by adding them in a newDatasetVersiononce humanly reviewed and using this enrichedDatasetVersionfor further training. The philosophy behind that by usingDatafrom the ground to retrain frequently ourModelVersionwe ensure its performances over time and avoid Data drift - Continuous training is part of the pipeline that triggers and orchestrates automatic
ModelVersionretraining once the Training Data has been enriched to enoughDatacoming from the ground. - Continuous deployment is part of the pipeline that exports the retrained
ModelVersionas a new version and potentially deploys it automatically on the impactedDeploymenton Picsellia.
An automatized processAll those steps are crucial to building a customized and automatized Data Pipeline. Once setup you'll be able to retrain and redeploy improved
ModelVersionwithout any human action (except the prediction review)
To set everything up, you need to access the Settings view of your Deployment and browse all tabs to define each step of your Data Pipeline.
To activate the computing of unsupervised metrics and the Feedback Loop, go into the related Settings tabs.
Select the DatasetVersion used to train the ModelVersion deployed for the Training Data tab and the DatasetVersion enriched with production Data for further ModelVersion retraining in the Feedback Loop tab.
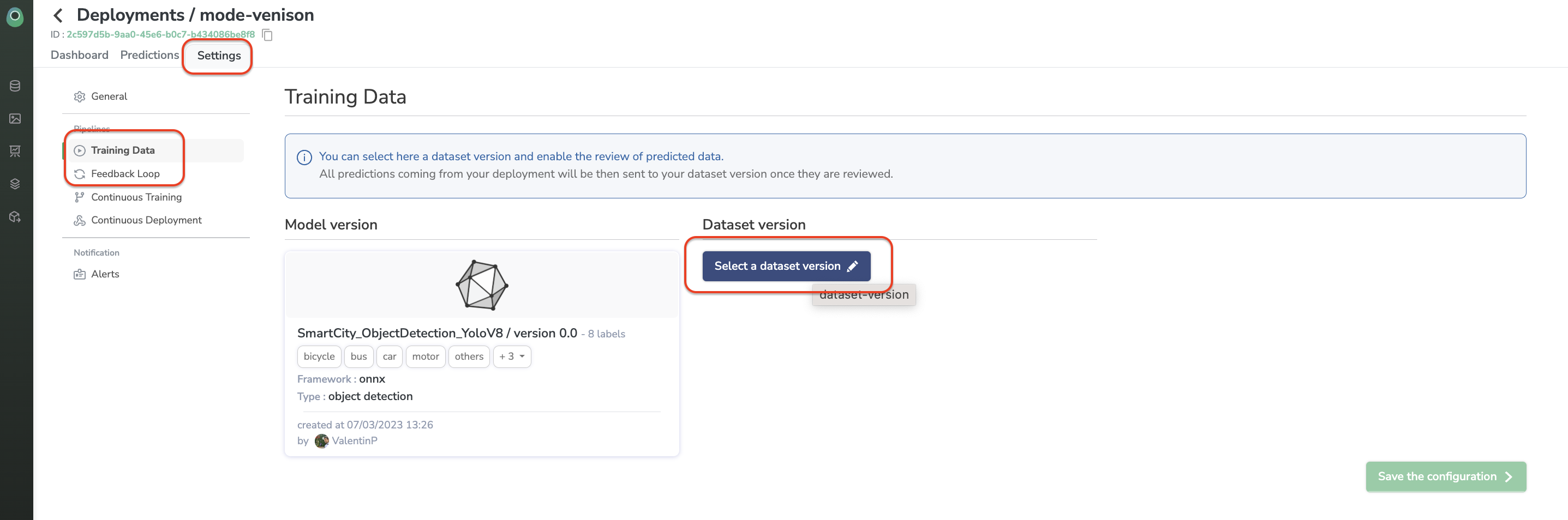
Be patientWhen setting up the dataset in Training Data, the initialization can take several minutes before the computing of unsupervised metrics become available.
Continuous Training and Continuous Deployment can also be initiated from this “Settings” view.
For continuous training, you will be asked to define the retraining ModelVersion parameters such as the project, the ModelVersion to retrain, the training DatasetVersion, and training hyperparameters:
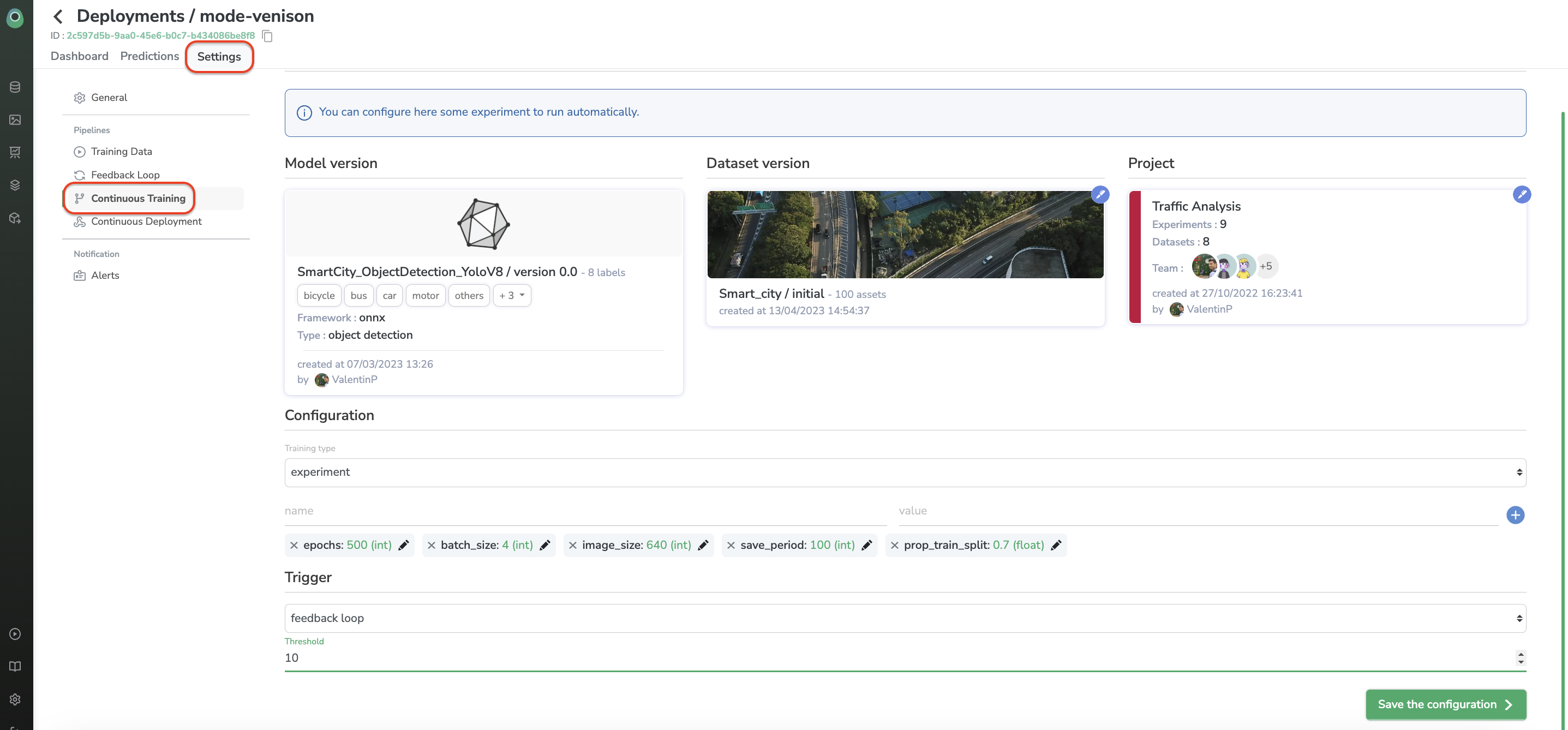
It is important to know that this new training and deployment loop is activated when the number of predictions reviewed by a human and added to the dataset reaches a threshold defined in the "Trigger" subpart.
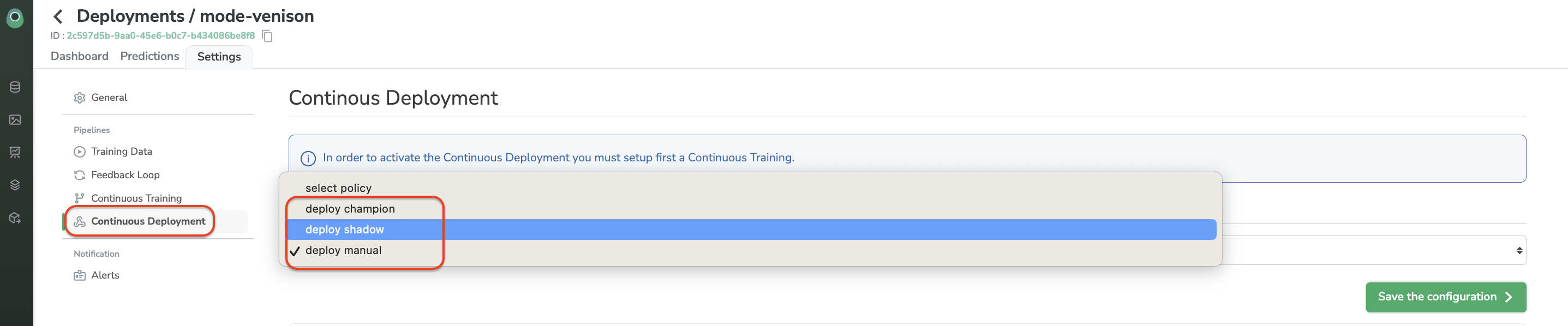
Regarding the continuous deployment, you've three possibilities:
- Deploy Shadow: The new
ModelVersiontrained through Continuous Training is deployed as a shadowModelVersionof the currentDeployment. It means that Champion and ShadowModelVersionwill makePredictionfor further inferences. It is the best way to assess that the newModelVersionis over-performing the previous one before turning it into the champion. - Deploy Champion: Replace the Champion
ModelVersionwith the newModelVersioncreated through Continuous Training. Further inferences will be done by the newly createdModelVersion. - Deploy manual: Do not deploy the new
ModelVersioncreated through Continuous Training. This newModelVersionremains stored on your Private Model Registry.
You can ensure that your whole Data Pipeline is well activated from the Dashboard view:
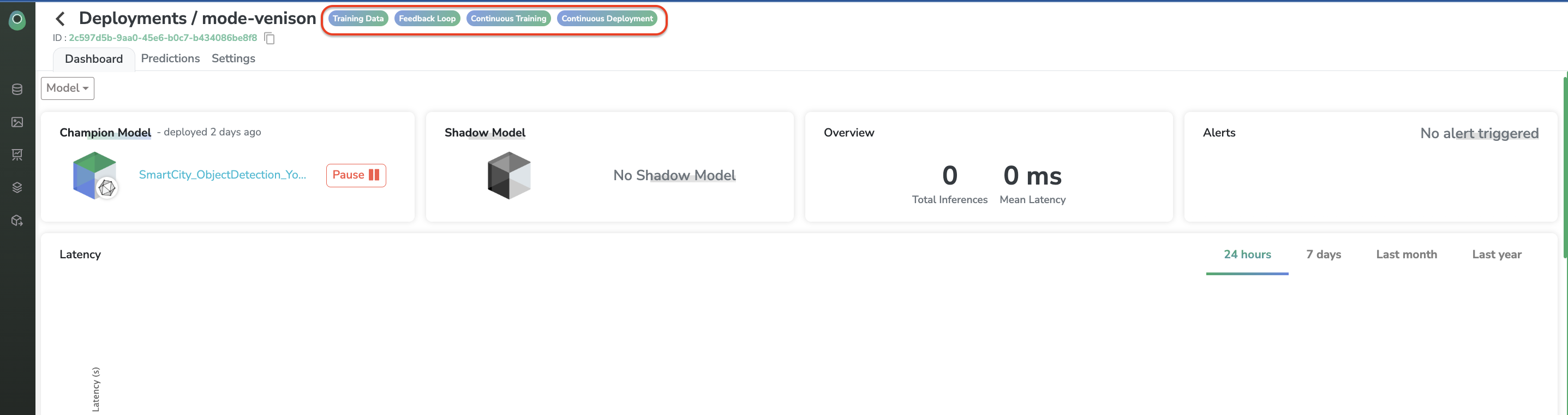
The "Settings" tab also allows you to update the confidence threshold and the name of yourDeployment
Updated about 1 year ago