🥑 Getting Started
This page will help you get started with Picsellia. You'll be up and running in a jiffy!
What is Picsellia?
Picsellia is the one-stop place for all the life-cycle of your Computer Vision projects, from ideation to production in a single platform 🚀.
Our mission is to give you all the necessary tools to relieve the burden of AI projects off of your shoulders. As a Data Scientist / ML engineer/researcher you shouldn't worry anymore about the following steps:
- 💾 Data Management
- 📈 Experiment Tracking
- 🔬 Hyperparameters Tuning
- 📘 Model Management
- 🚀 Model Deployment
- 👀 Model Monitoring
Philosophy: code-first or low-code, you choose 😀
As we know, you are most likely to like your IDE and have full control over your training code, that's why all the components from Picsellia are accessible from our Python SDK or through our APIs.
But sometimes, the R&D team needs to pass the ball 🏀 to the product team that won't be comfortable with manipulating huge code. That's why you can also manipulate everything done on Picsellia with a simple and intuitive platform, that way, everyone is happy! We like happy people :)
From uploading data to model deployment, you can do everything either from the platform or from your code.
We really hope you will find everything you need for your projects. If you have any feature request, please write us on one of our channels. (You can talk with us in English or French, we prefer English though so everybody on the channels can understand 😌)
Features
To help you figure out what you can or can't do with Picsellia, here are the main features that we developed that can cover many aspects of your projects. Don't hesitate to dig into each feature to see how you can achieve what you want, or just ask us!
Data storage and indexing
Isn't it a pain to find a way to store all your data and share it with your team in a way that is accessible easily for all your experiments and projects?
That's why we created the Datalake, where you can do the following to all your data:
- Store
- Index
- Search
- Visualize
To learn more about the Datalake: 👉 Browse the full documentation
Dataset creation
To let you iterate over your data while being sure you don't lose everything along the way, we provide a dataset management solution which is a powerful versioning tool where you can:
- Create different versions of datasets.
- Annotate your data.
- Clone images / labels / annotations from one dataset to another in a granular way.
- Merge your annotations in one click.
To learn more about Datasets: Learn how to Create a Dataset
Data Annotation
If you stored some data in your Datalake and created one or several Datasets, you can now annotate your images with geometric shapes for object detection, segmentation, key points, and classification.

To see all the possible ways to annotate your data, please refer to this piece of documentation:
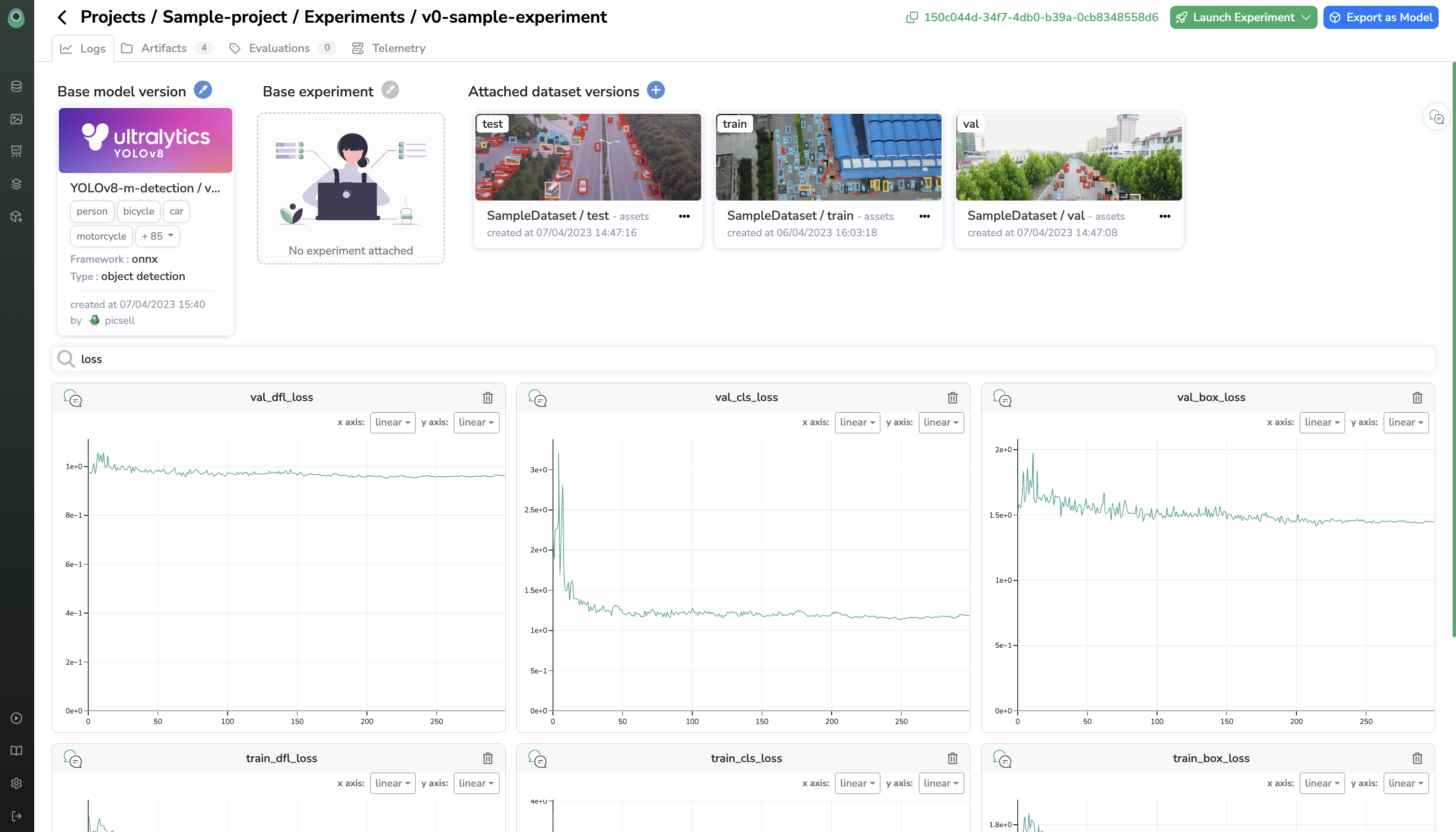
Experiment tracking
Have you ever felt that you are a notebook collector? That they lack interactivity or on the contrary that you have no way to collect your logs and results efficiently for your algorithms when they run on remote machines?
Well, that's why we have designed a full-fledged experiment tracking system that allows you to perform a lot of things:
Model Management
You can export your experiments and add them to your model's registry in order to:
- Use them to kickstart your experiments (for example fine-tuning a model on your own data).
- Deploy them for inference with an API endpoint.
- Add some documentation so everyone knows what your model does and how to use it.
- Share them with your team or organization.
Model Deployment (Tensorflow and ONNX)
Now that you have trained your own custom model or using one from the model HUB, you might want to expose it to the world (or at least your company or client) with an API endpoint, hopefully, you can do it with one click only from the Picsellia interface, or from the Python SDK and then make predictions using your API token.
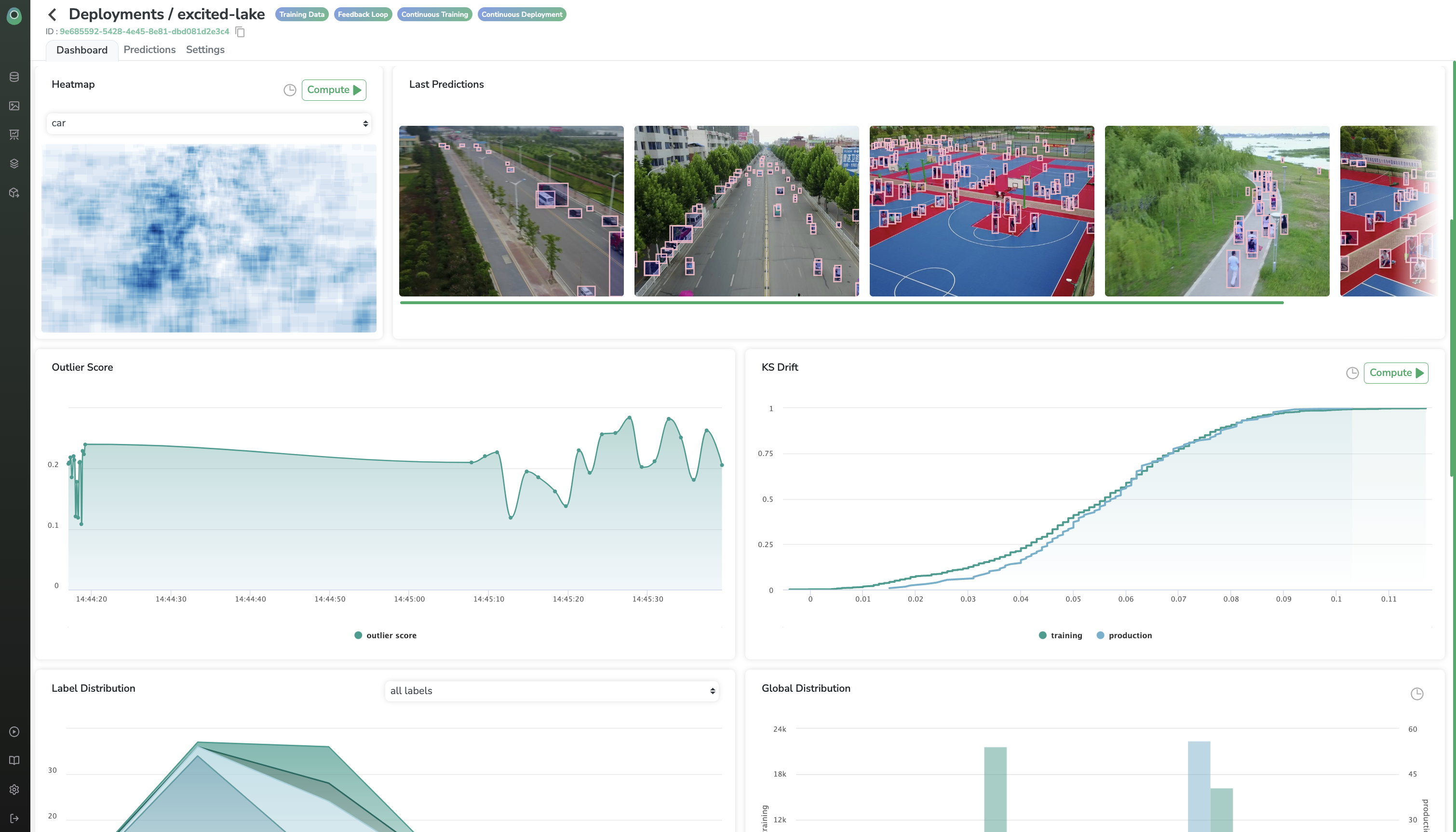
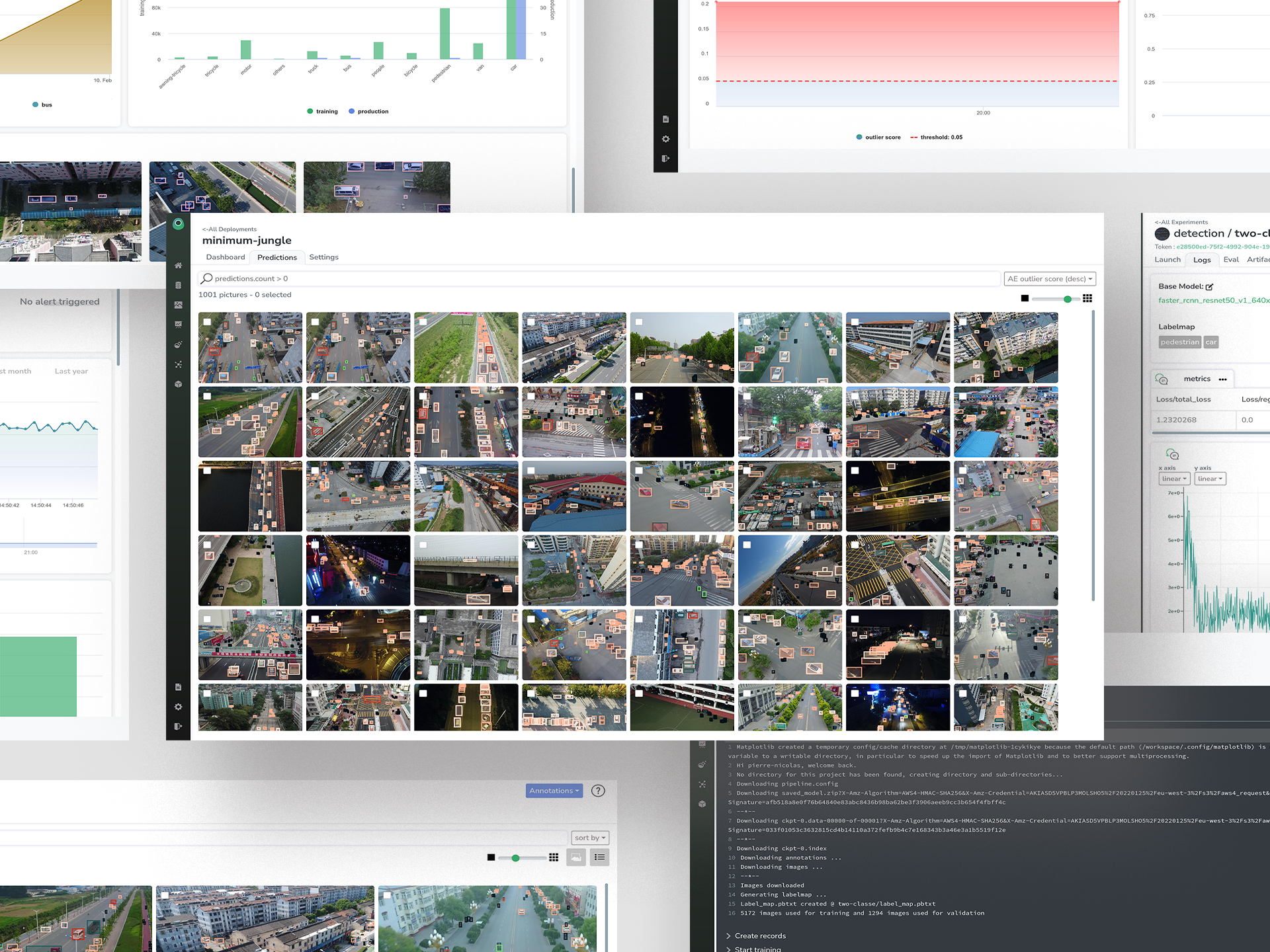
Model Monitoring
You can log all your predictions to Picsellia in order to visualize it and access a lot of monitoring metrics like KS Drift, AE Outlier, or just inference time :)
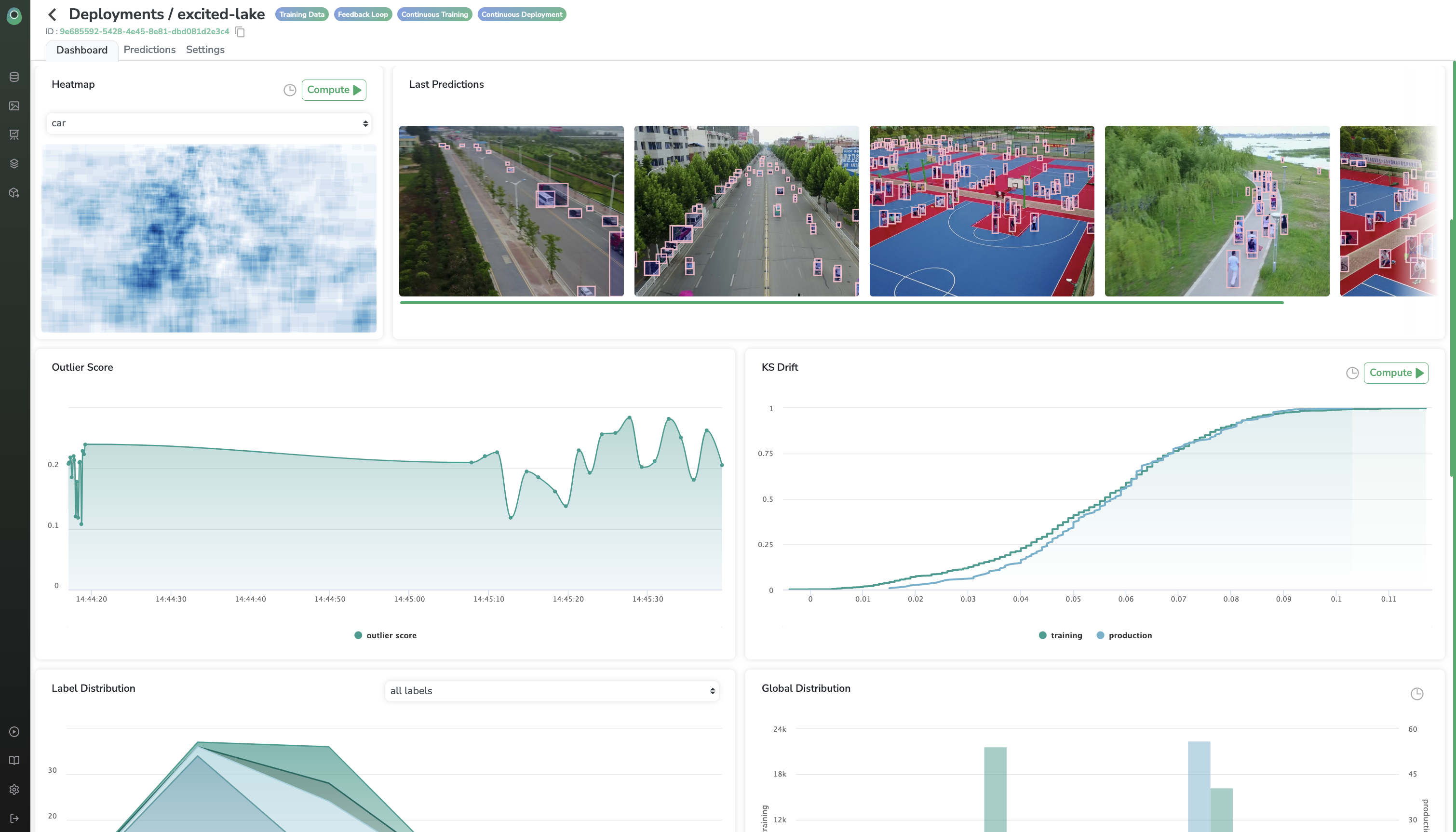
Updated about 1 year ago