2. Use Public / Common Data Processings
Our journey starts in the Processings page, that you can access right below the Datasets tab in the Navbar:
If you go there, you will have access to all the Processings created by the Picsellia team alongside the ones you created.
Let's have a look at this page

For now, we can see that only two Processings are available. Given their names, we can conclude that they can be used to pre-annotate our datasets with either YOLO or Tensorflow models.
Let's click on the edit icon of yolo-preannotation to see what's inside
You will see the same interface regardless of the Processing you want to edit is one of yours or ours.
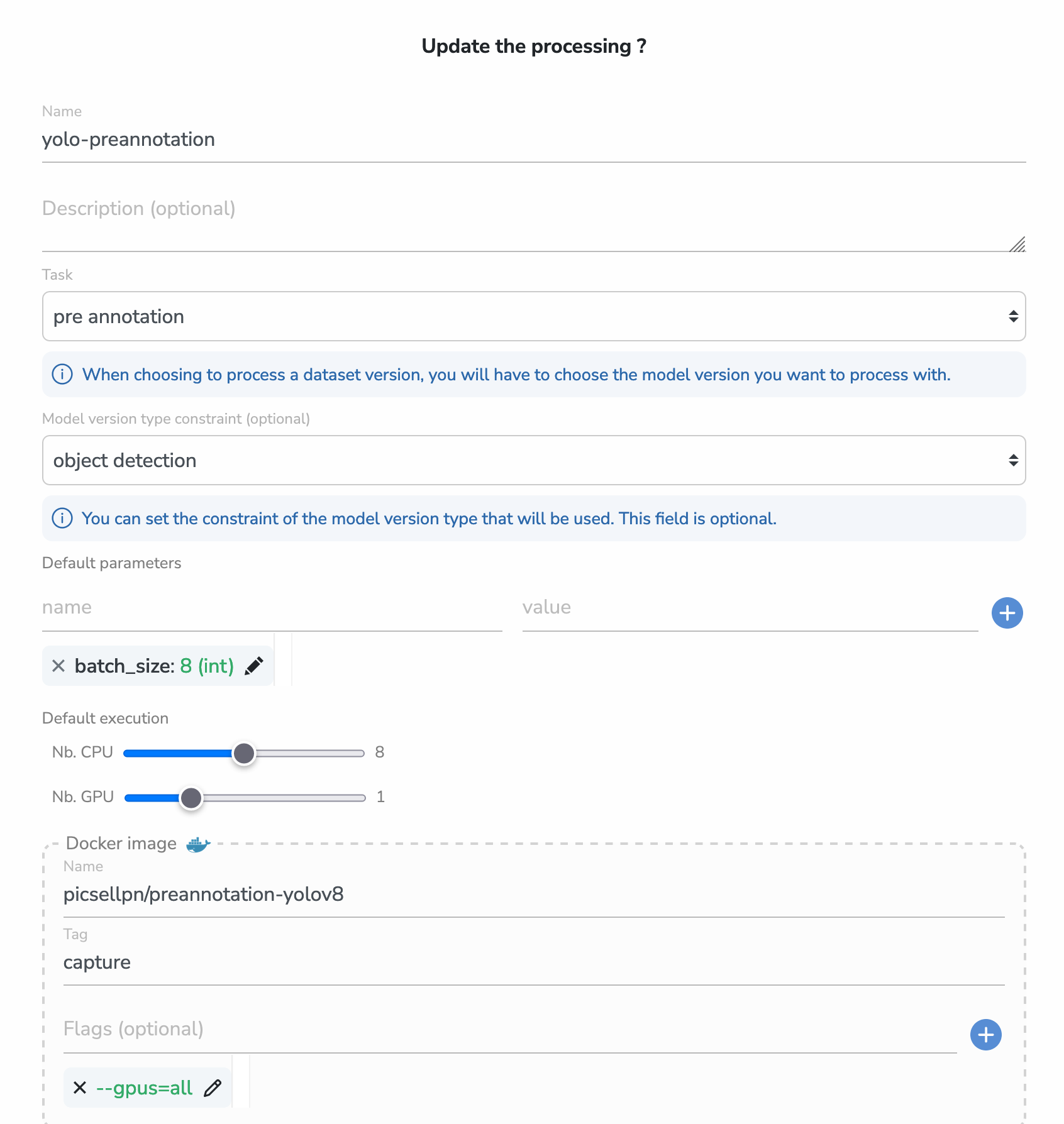
- First of all, you can see the name of the Processing. We tried to make them as explicit as we could and you should do the same! Here we can guess that this Processing can be used to pre-annotate Datasets with YOLO models
- Then we have the task of the Processing. This is used to know the main purpose of the Processing. As in this case it refers to the task pre-annotation, it means that we will be able to choose a model before launching the Processing
- The next field is the model version type constraint. As we chose a pre-annotation task, we can specify the allowed type of model that can be use to perform the pre-annotation (more about constraints in the last part of this guide).
- Now here is a field that should remind you our Experiment system 😉 Those are defaults parameters that will be editable before launching the Processing and accessible from the launched script.
- Then, you can choose the number of CPU and GPU needed for the execution of your script. We are going to allocate those exact resources when you launch the Processing.
- And finally, you can see the name of the Docker image as it is stored in the Docker Hub or a private registry. This image will run a container where our pre-annotation script lies, and it will be launched with the flags that you can see just below. Here, as our image needs a GPU to execute, we just give this flag that enable GPU support for a Docker container.
That's it for the Processings Information! Now let's see how you can actually use it on your own Datasets
Updated 9 months ago
Continue Reading