Datalake - Explore your Data with Embeddings
The Picsellia Datalake offers several features that rely on the embeddings that are computed for each image, those feature allows a smooth and efficient exploration of a large volume of images based on mathematical methods.
In detail, based on the embeddings computation, in a given Datalake, you'll be able to:
- Perform similarity search
- Query your data with the Text-to-image search
- Explore the embeddings precisely with the integrated UMAP projections map
1. How to configure it?
First of all before using the features that rely on the embeddings computed for your images, you need to activate this computation. To do so, you need to access the Datalake settings, especially the Visual Search tab and click on Activate:
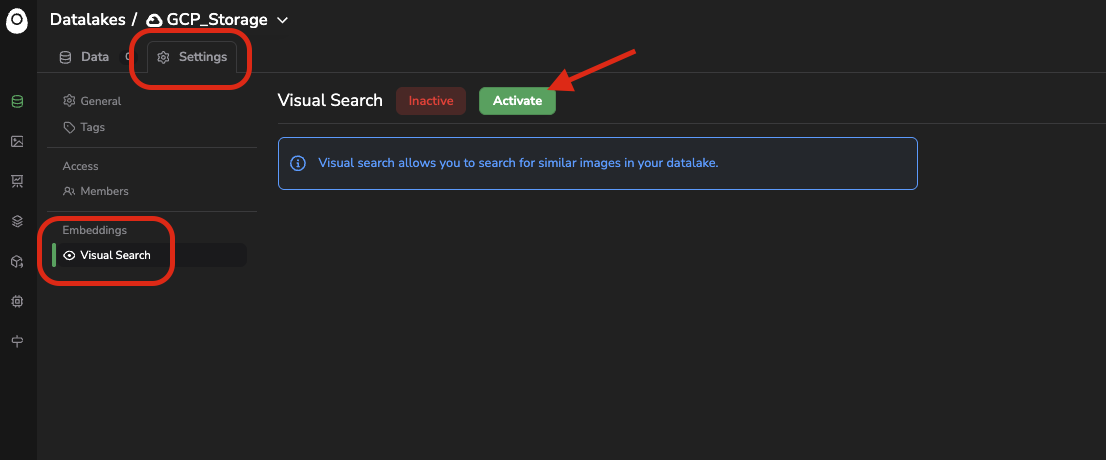
Access the Visual Search configuration page
You need to have the Admin rights on the current
Datalaketo access its Settings page
Please note that the embeddings computation is Datalake related, meaning that if you have several Datalake, you'll need to perform this activation for every Datalake.
Once activated, the computation of the images that are already in your Datalake will start, the compute time obviously depends on the volume of images in your Datalake. This computation can be tracked thanks to the progress bar or directly from the related internal Job created and accessible in the Jobs tab.
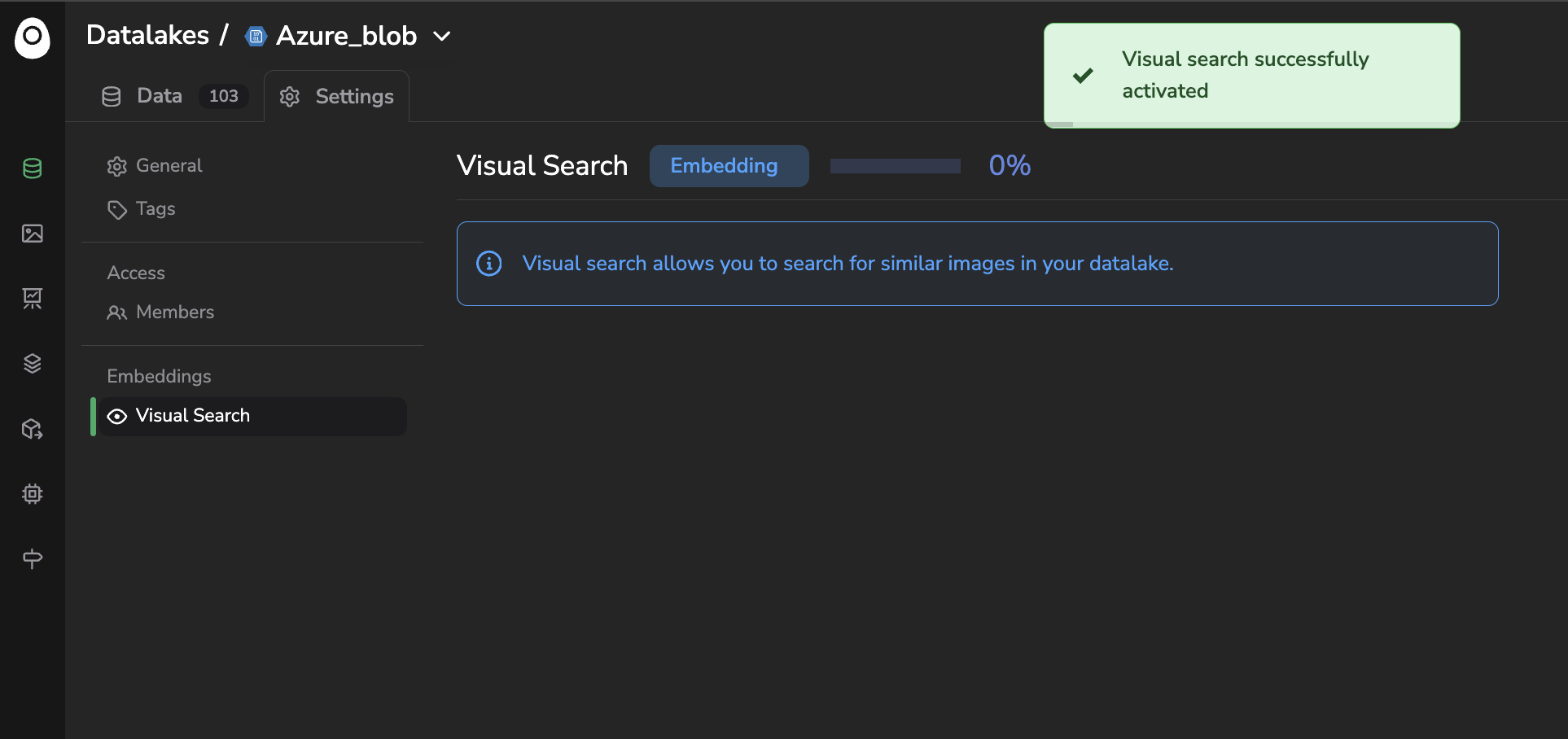
Activation of the Visual Search
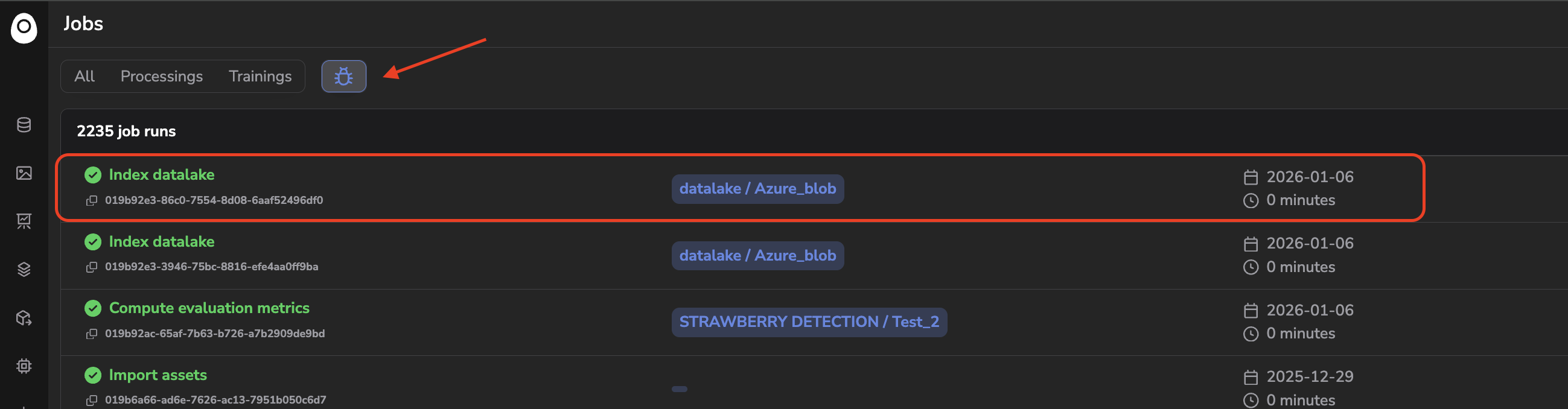
Embeddings computation Job
Once the computation is over, you'll have access to an embeddings status overview that details the number of images treated successfully and also the ones that have not been computed for any reason:
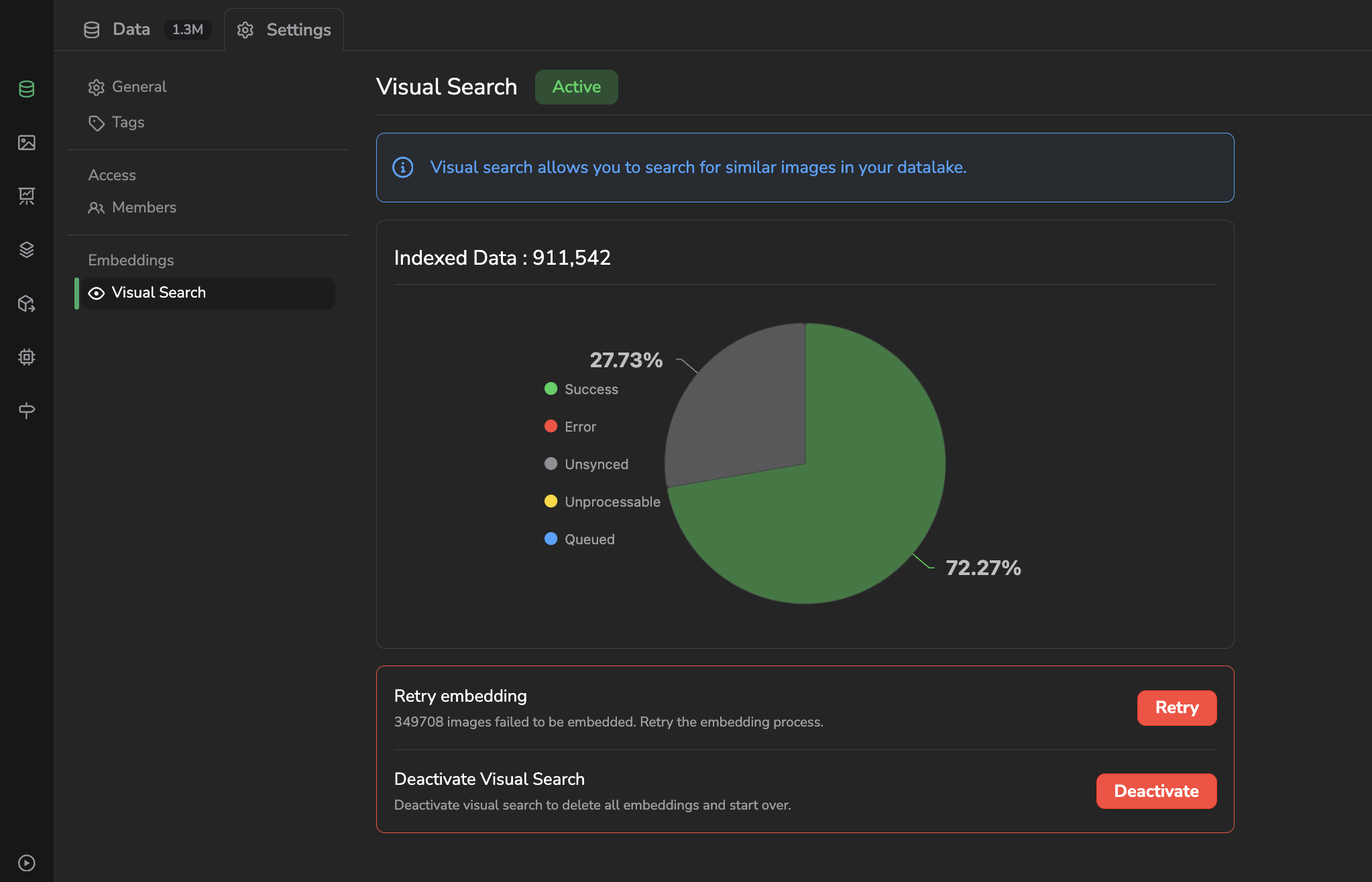
Embeddings computation overview
As it is the case in the above screenshot, it happens that some images can not be computed, either due to an isolated issue during the computation process or because some images are not in a format that is handled. In both cases, you can relaunch the embeddings computation for all the images that are in a given status using the Retry button:
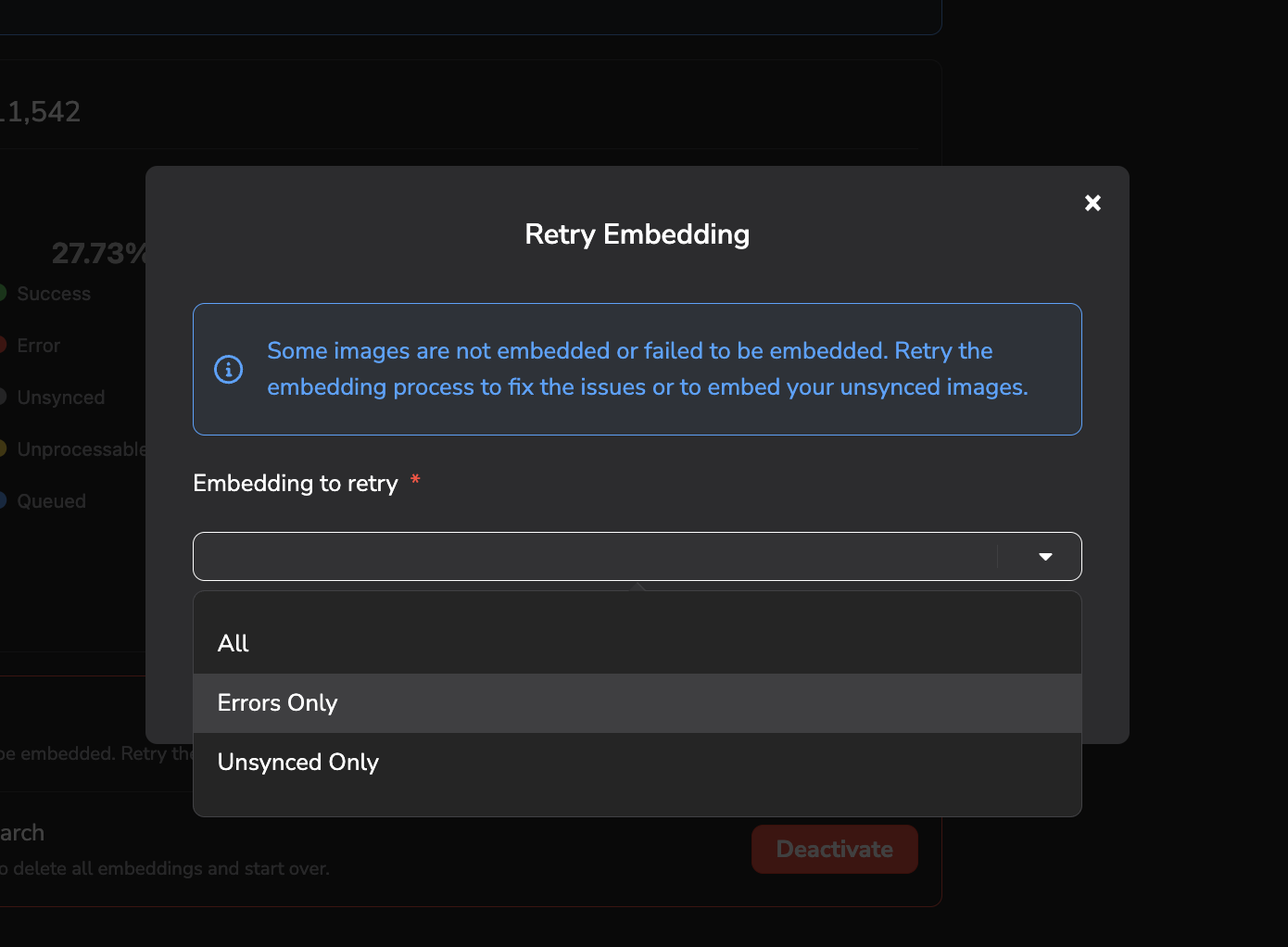
Retry embeddings computation
Once the computation is over, the Active flag appears. This means that from now on, each new image uploaded to the current Datalake will, if possible, be computed to generate an embedding from this one.
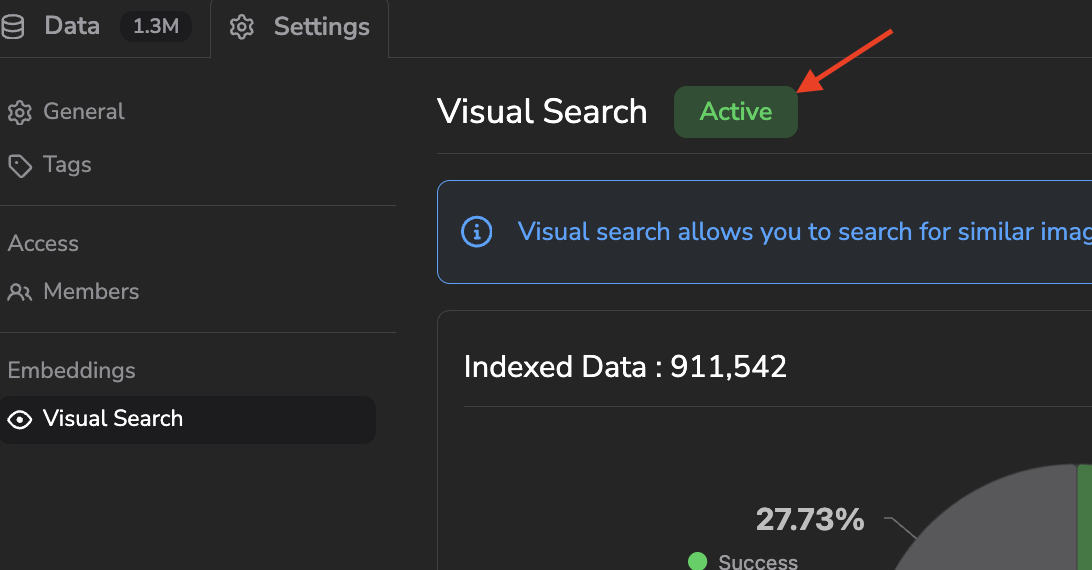
Visual Search feature status
Please also note that you can deactivate the embeddings computation at any moment by clicking on Deactivate, this will, as a consequence, delete all the embeddings already computed for the current Datalake so please be very cautious while using this button.
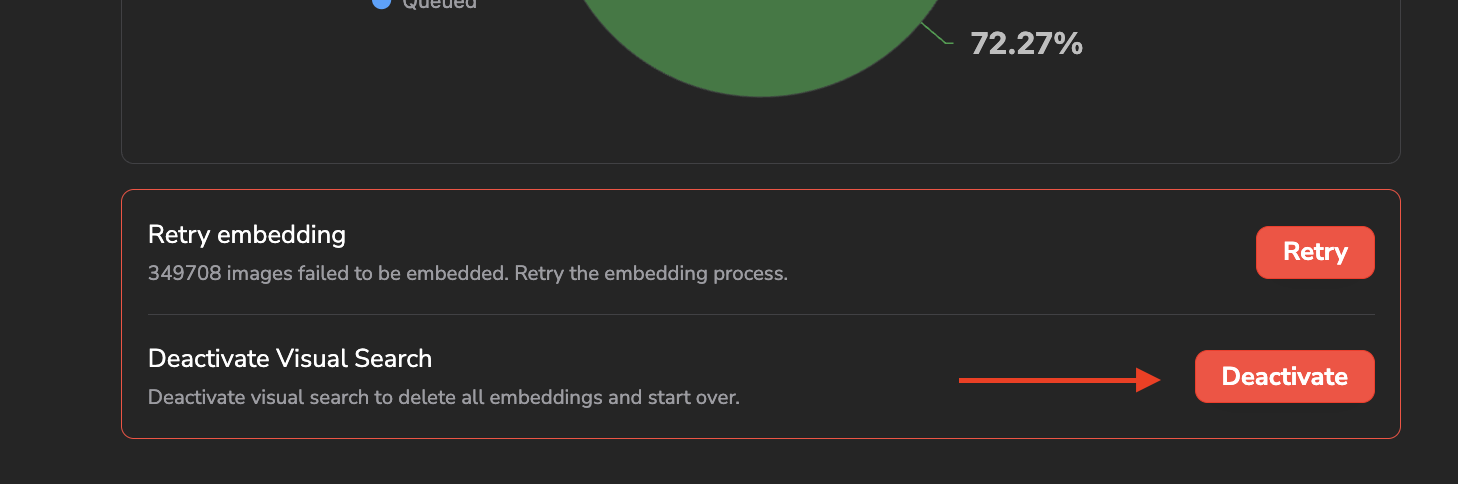
Visual Search deactivation
Let's talk quickly about the technologies that are used behind this embeddings computation.
Basically, it is the library open_clip that is used to generate one embedding vector per image. In particular, it is the model ViT-B-16 with the weightsdatacomp_xl_s13b_b90k that are used by default. Once generated, each embedding vector is stored in a QDrant Vector Database and especially the Vector Search Engine to implement the different exploration features that will be detailed below.
Use your own embeddings model ?
The Picsellia embeddings system has been build by design to handle any type of embeddings model, so if you want to use your own model to compute the embeddings of your
Datalake, please reach out the Picsellia team in order to setup this specific configuration.In case you need more then a generic OpenClip model to compute and explore your embeddings, you can also leverage the Experiment Tracking feature of Picsellia to fine-tune the generic OpenClip model on your own images and captions. This would then allow you to quickly train and integrate an embedding model that generates insightfull vectors in your particular context. For that need also, please reach out the Picsellia team to proceed.
Now that the Visual Search feature is fully activated and the embeddings computation is over, let's detail together the different features that will leverage them to perform image exploration.
2. Similarity Search
The first and most common way to leverage the embeddings is through Similarity Search. Basically, it allows identifying the images that look the most like the selected one.
To find the X more similar image from your Datalake for a selected one, you just need to select it directly among your Datalake, click on Find Similar, type the number of most similar images to search for, and click on Search.
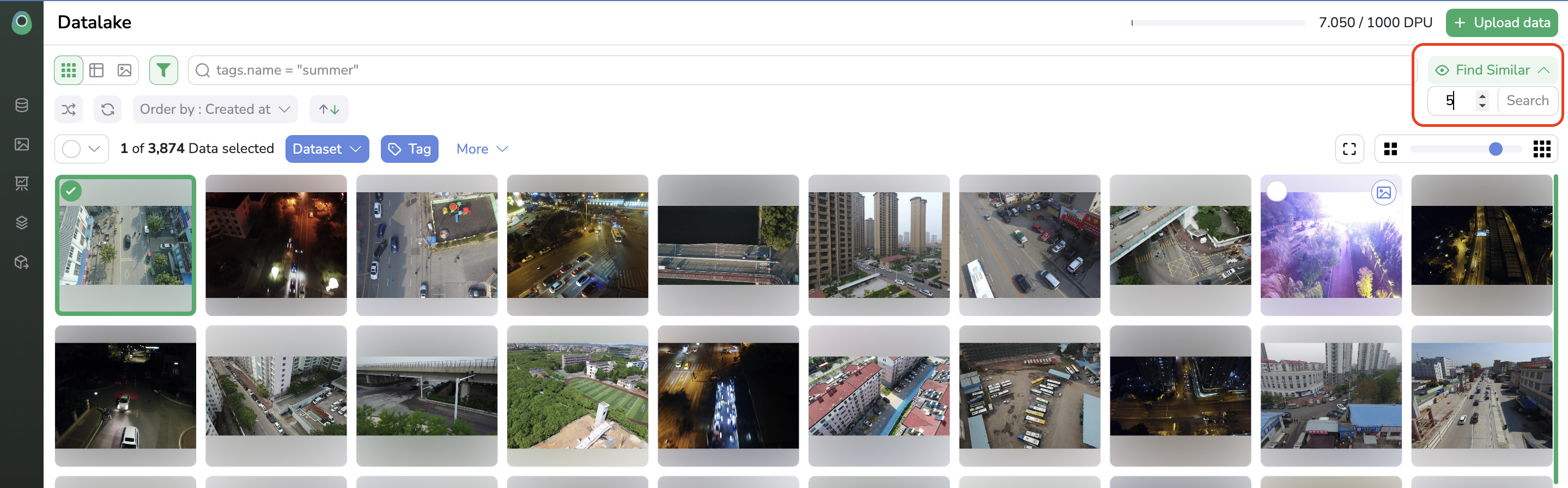
Use SimilaritySearch
The Similarity Search button is accessible only if one image is selected
Once, more similar images are found by Picsellia, they will be displayed in the Datalake overview as shown below:
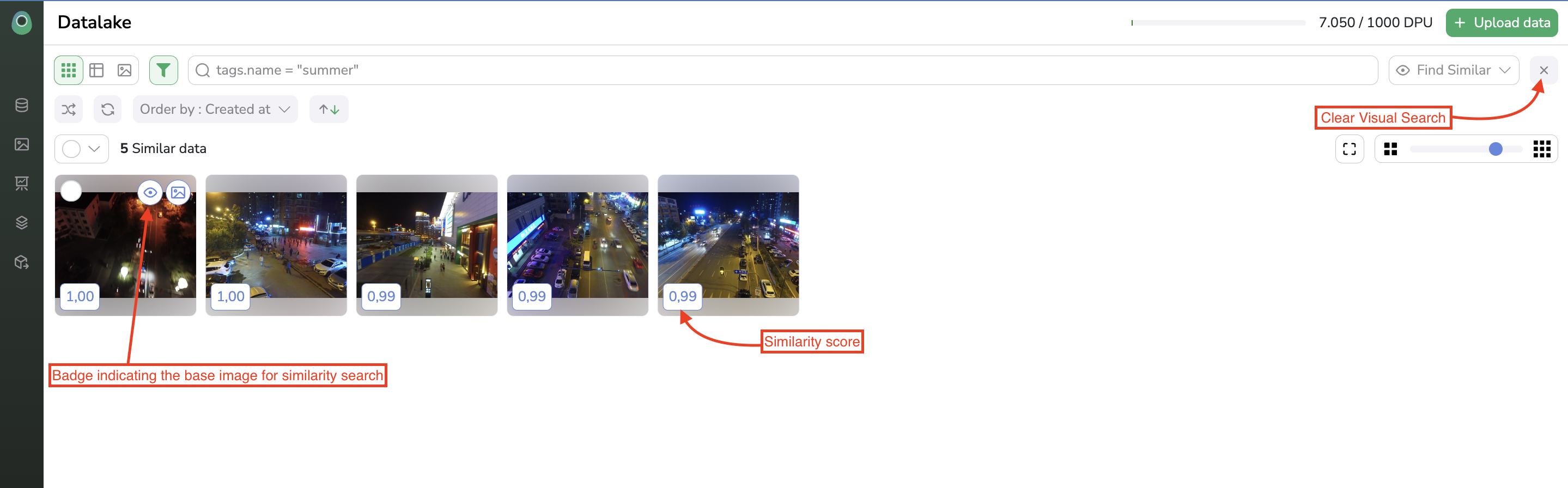
Similar images visualization
3. Text to Image search
You can also explore your images not based on the similarity with a given image aspect, but based on a text prompt. This is made possible by the captioning embedded in the OpenClip model.
Basically, it allows identifying the images that correspond the most with a given text prompt.
To find the X images from your Datalake that fits the most a text prompt, you just need to click on the Text-To-Image icon, prompt your query, type the number of most relevant images to search for, and click on Search.

Once, more relevant images are found, they will be displayed in the Datalake overview as shown below:
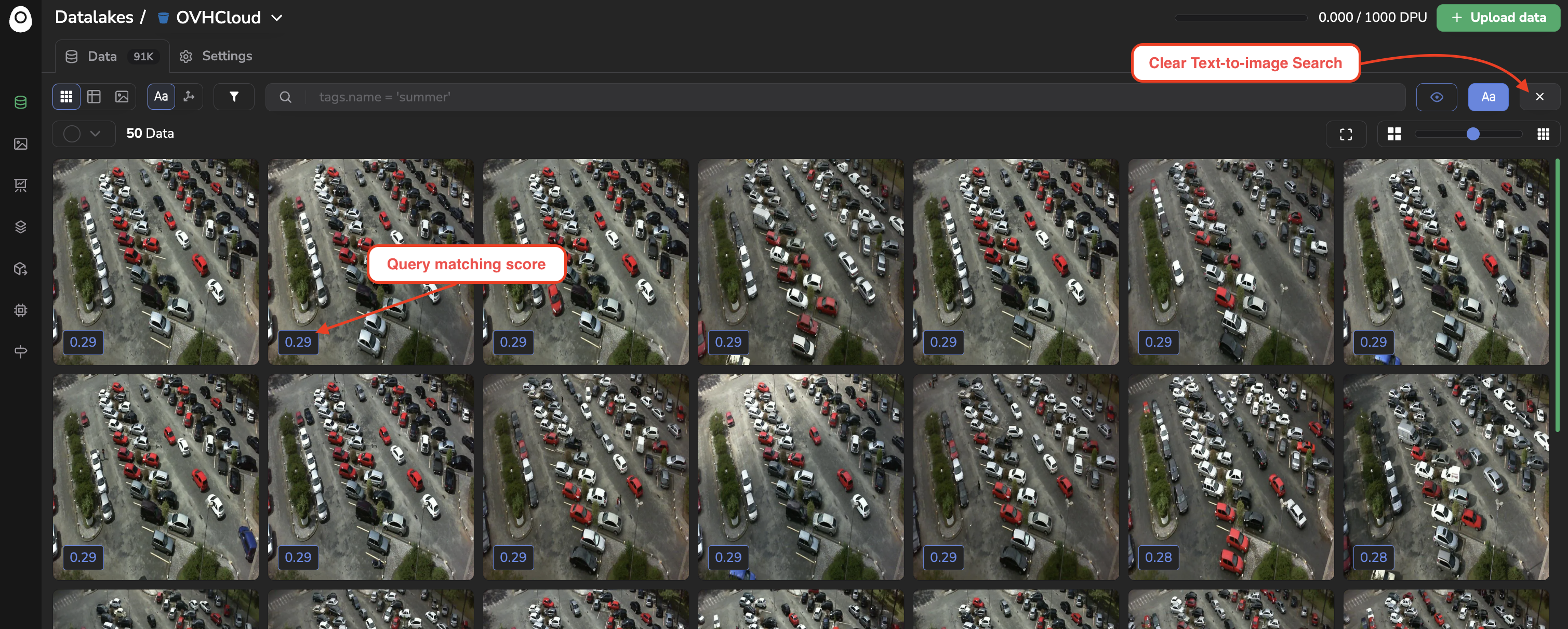
4. UMAP Projections
The last way to leverage embeddings in your Picsellia Datalake might be the most powerfull and flexible, this one is the UMAP projection and visualisation of every embedding vector computed for the current Datalake.
Basically by cliking on the UMAP Projection button you'll access a scatter plot displaying the point cloud of all your embeddings vector computed and projected follwing the UMAP method.
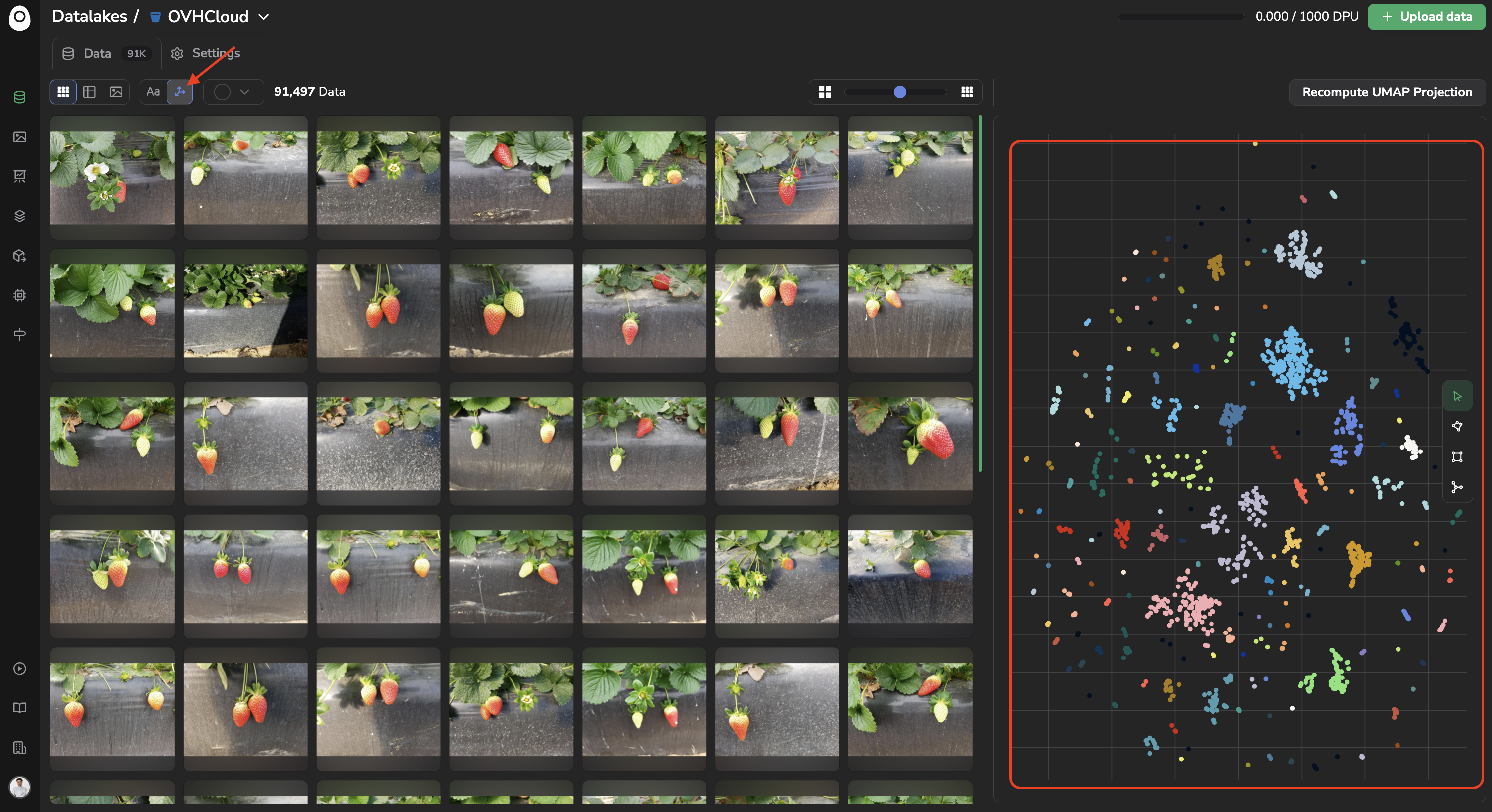
Each point here represents one or several images (depending on the number of image considered).
The images that are visually closed with each other are grouped together using the DB SCAN clustering method and identified with the same color.
You can explore the embeddings point cloud by selecting a group of points using the polygon, rectangle or cluster tools, they will allow you selecting a bunch of points:
The images corresponding to the selected points will be highlighted in red and be displayed on the left panel:
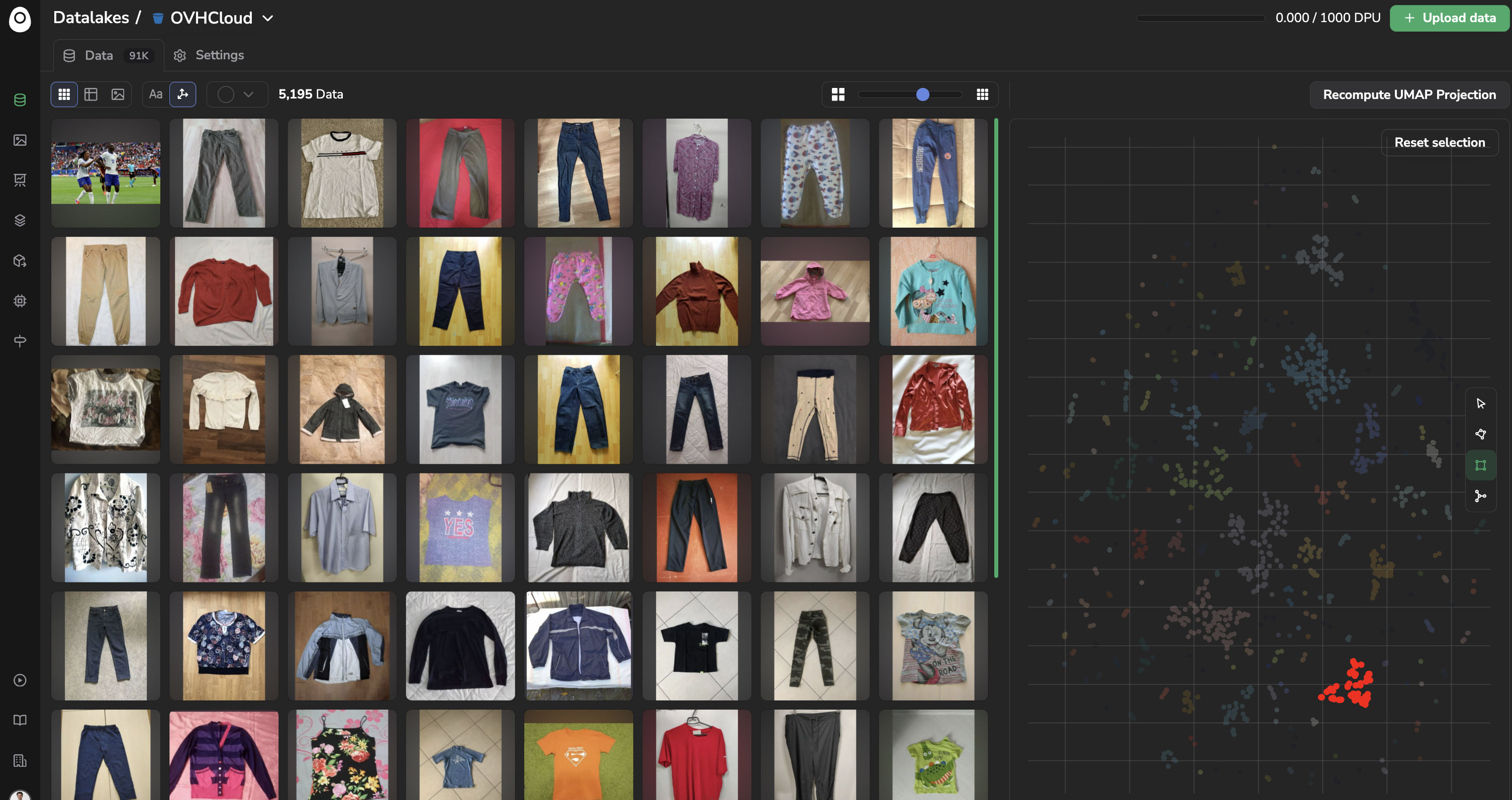
Please note that for now it is not possible to explore Datalake using at the same time the embeddings scatter plot alongside with the SearchBar. You can switch easily between the two exploration modes easily as long as the embeddings selection or query in the search are reset:
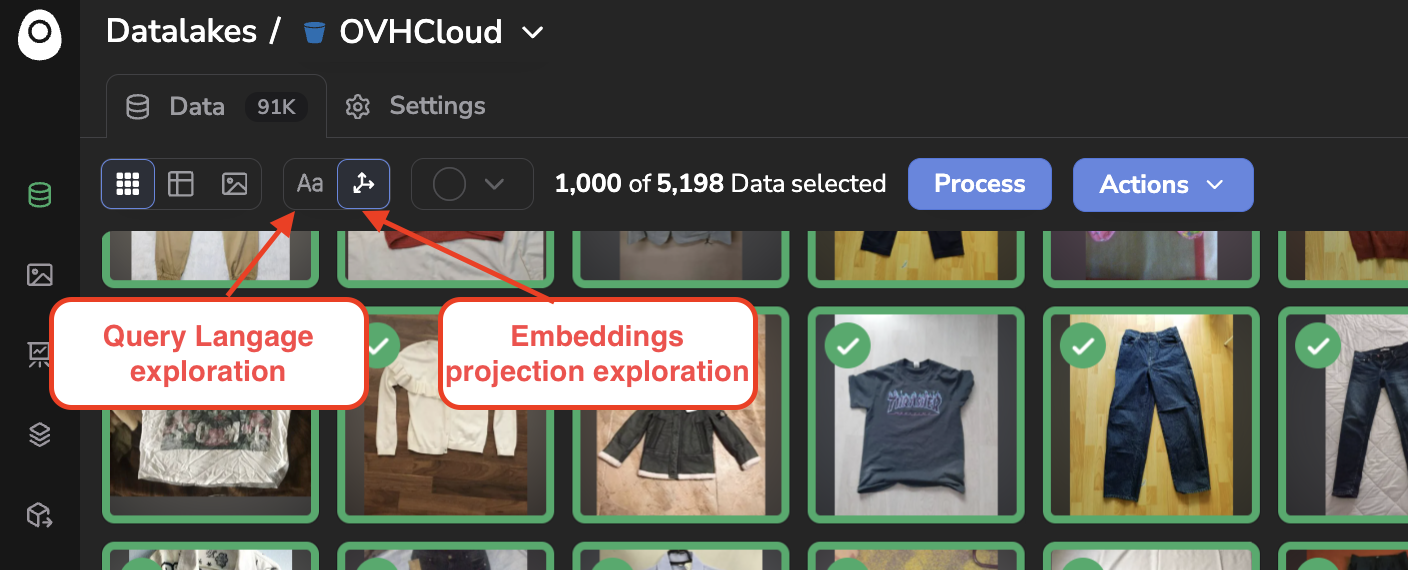
Nevertheless, once images have been filtered with the embedding exploration tools, they can be selected to get tagged, processed with a Datalake Processing or used to create a new DatasetVersion. You simply need to select the images and use the Process or Actions buttons as shown below:

A very illustrative use case, would be to identify the isolated points that are likely outliers or corrupted images, visualize them to validate it and tag them to retrieve them easily in the future.
To reset the embeddings selection you can click on "Reset Selection".
The compute of UMAP projection is not automatized so you can manually recompute the points cloud with all the latests images by clicking on Recompute UMAP Projection.
Please note that by recomputing the UMAP, you'll have the ability to set some UMAP and DBSCAN parameters as shown below:
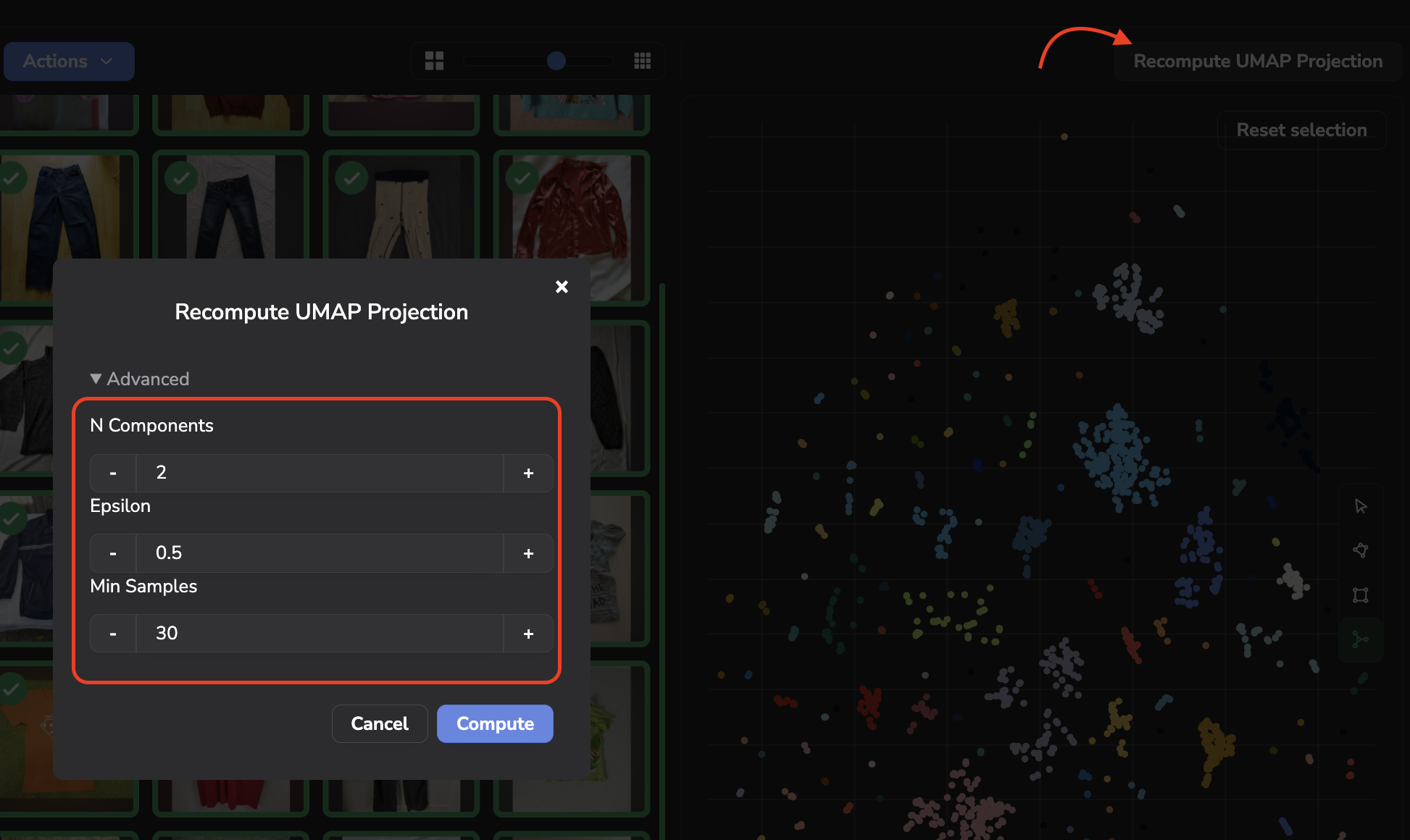
More details about the UMAP parameters are available here.
The DBSCAN parameters are the following:
- ε (epsilon): The maximum distance between two points for them to be considered neighbors.
- Min_samples : The minimum number of points required to form a dense region.
Updated 7 months ago